Data Analysis in SQL (Part 1)
해당 포스트를 시작으로 데이터 분석에 흔히 사용되는 SQL 쿼리문들을 간략하게 정리해보고자 한다. 사실 마지막으로 SQL을 사용한지가 벌써 꽤나 오래돼서 언젠가 정리해야지만 하고 계속 미루고 있었는데, 마침 이번 학기 대학원에서 열린 빅데이터 분석 경진대회의 데이터가 기업 내부의 데이터베이스를 통채로 추출한 덤프파일이여서 반강제적으로 SQL을 사용할 수 밖에 없게 됐다.. 뭐 이유야 어쨌든, 이후 포스트들에서는 MySQL이라는 DBMS를 이용해 데이터베이스에서 데이터를 조회 및 집계하는 쿼리문들에 대해 다룰 예정이다.
목차
SQL 시작하기
본격적인 내용으로 들어가기에 앞서, 데이터베이스와 관련된 기초적인 개념 몇가지만 짚고 넘어가도록 하자.
우선적으로, DBMS (Database Management System) 란 데이터베이스에 접근할 수 있게 해주는 시스템을 의미한다. DBMS는 SQL (Structured Query Language) 이라는 언어를 이용해 데이터베이스에 접근하는데, 이렇게 DBMS에 명령을 내리기 위해 사용되는 언어를 SQL이라고 부른다. 이를 간단하게 도식화해보면 아래와 같다. (이미지 출처)
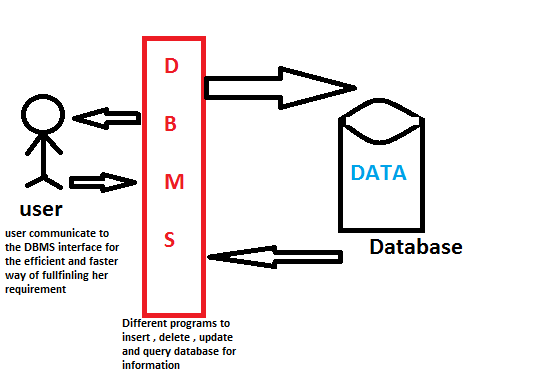
Illustration of DBMS
DBMS의 종류에는 여러가지가 있고 (MySQL, Oracle, MariaDB 등) 각 DBMS마다 사용되는 SQL 문법이 약간씩 다르지만 SQL의 표준 문법에서 크게 벗어나지 않기 때문에 딱히 걱정은 안해도 된다. 우리가 사용할 MySQL도 이러한 DBMS 중 하나라고 할 수 있는데, 다양한 DBMS 중에서도 MySQL이 선호되는 이유는 비교적 가볍고 무료라서 쉽게 사용할 수 있다는 특징 때문이 아닐까 생각한다.
그렇다면 MySQL은 어떻게 사용하는 것일까? MySQL Workbench 라는 응용 프로그램을 이용하면 MySQL을 GUI 환경에서 쉽게 사용할 수 있다 (MySQL 버전의 통합개발환경 (ex. 파이썬의 PyCharm, R의 RStudio) 정도라고 생각하면 편하다). 맥OS를 기준으로, MySQL은 다음의 사이트 에서, Workbench는 다음의 사이트 에서 다운받을 수 있다. 성공적으로 설치가 되었다면 맥의 시스템 환경 설정에서 아래의 사진과 같이 서버를 활성화시켜주자.
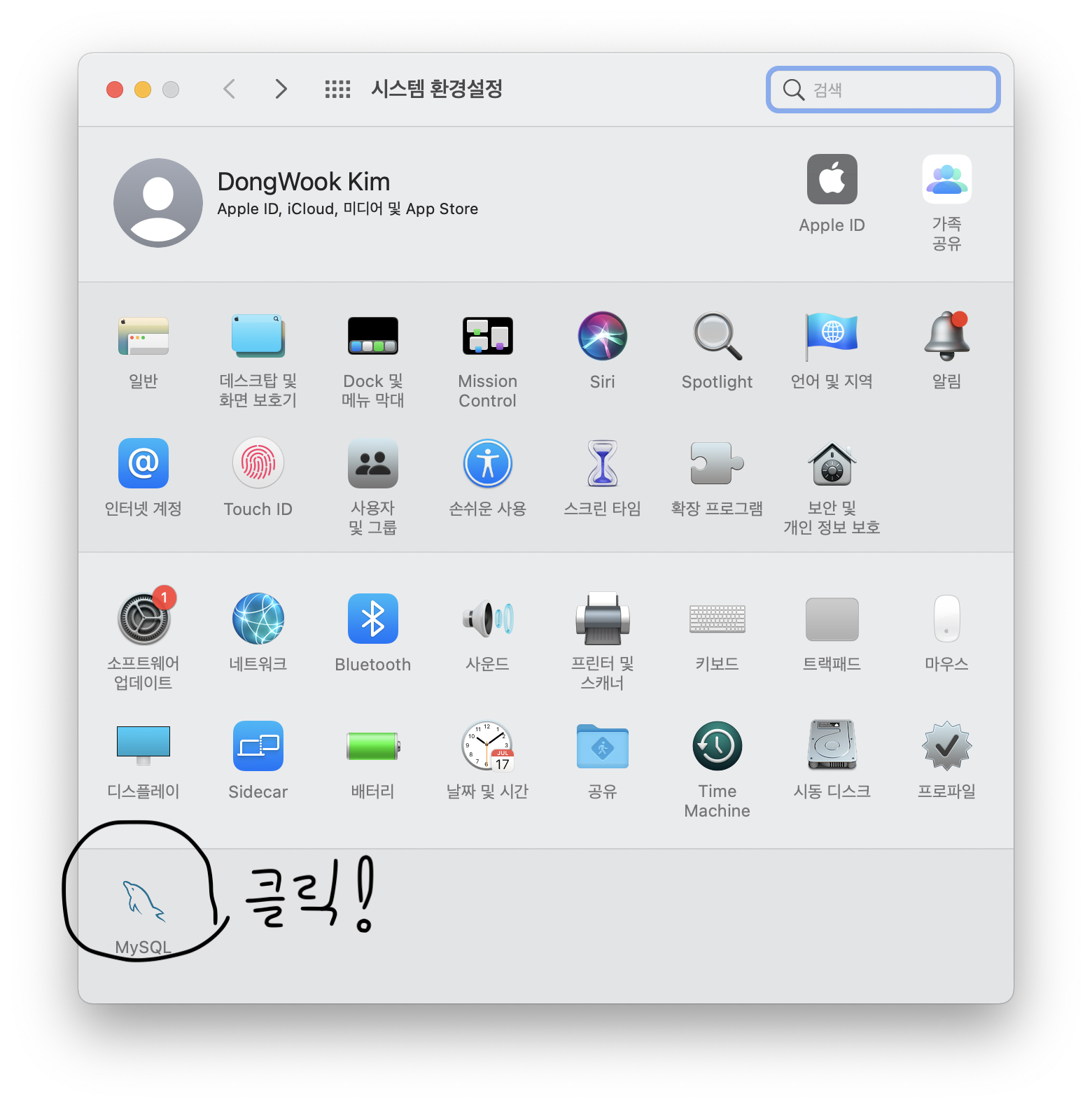
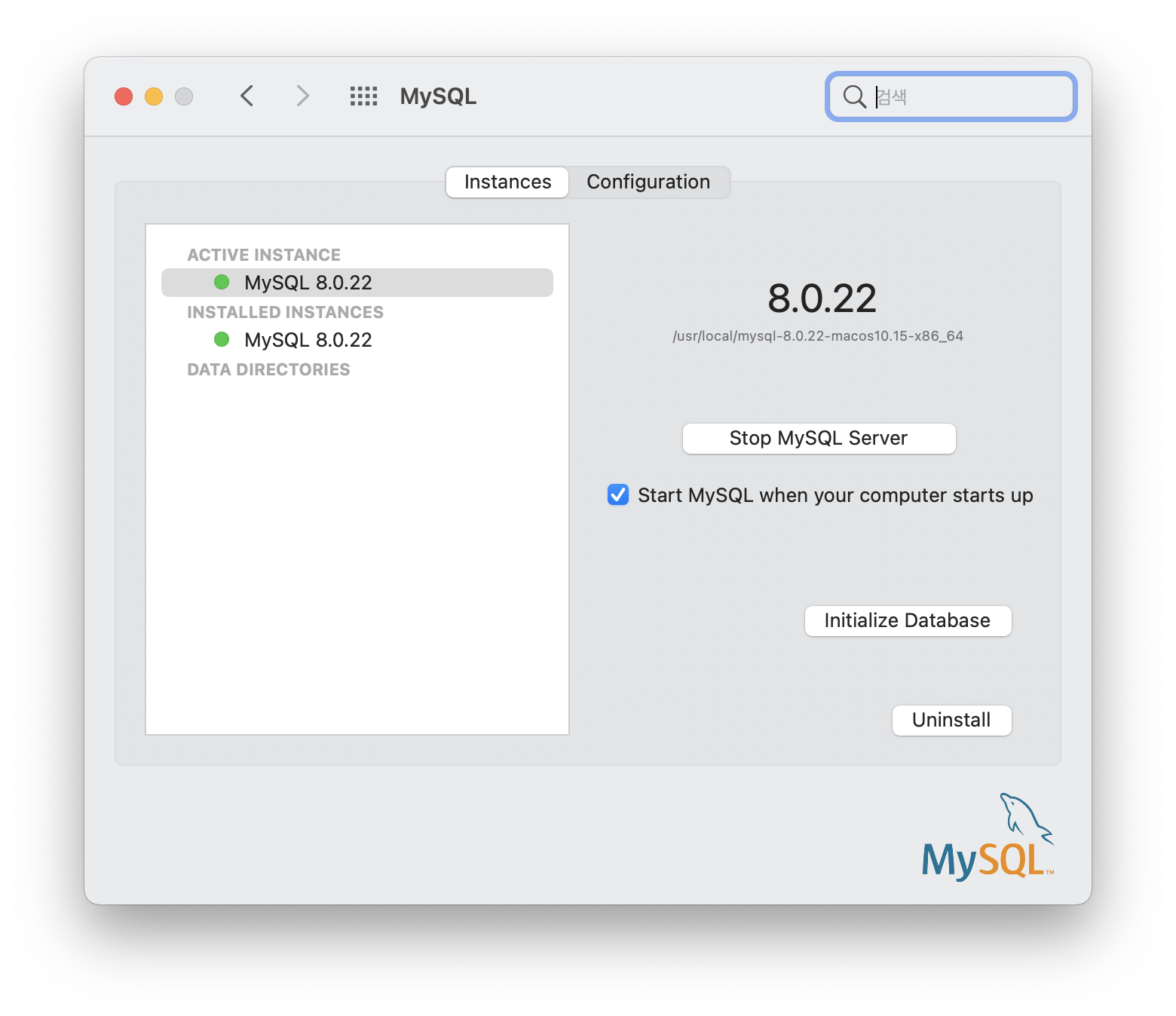
서버 활성화까지 완료되었다면, 이제 Workbench를 이용해 MySQL 서버에 접속할 수 있다.
앞으로 해당 쿼리창을 이용해서 여러가지 작업을 수행할 것이다. 이제 본격적으로 쿼리문들에 대해 살펴보도록 하겠다.
데이터베이스 생성
다음의 쿼리문을 실행해서 my_db라는 데이터베이스를 생성하자.
- 참고: SQL에서는 데이터베이스를 스키마 (Schema) 라고 부른다.
데이터 불러오기
데이터베이스가 잘 생성되었다면, 해당 데이터베이스에 분석에 사용할 데이터를 불러오도록 하자. 데이터에 대한 간략한 설명은 다음과 같다.
use_log.csv: 2018.04 부터 2019.03 사이의 헬스장 회원들의 이용 로그 데이터customer_master.csv: 2019년 3월 말 시점에서의 회원 데이터class_master.csv: 회원 종류 데이터campaign_master.csv: 회원권 할인 행사 데이터
해당 데이터들은 여기서 다운받을 수 있다.
아래와 같이 Table Data Import Wizard를 이용하면 어렵지 않게 데이터를 불러올 수 있다.
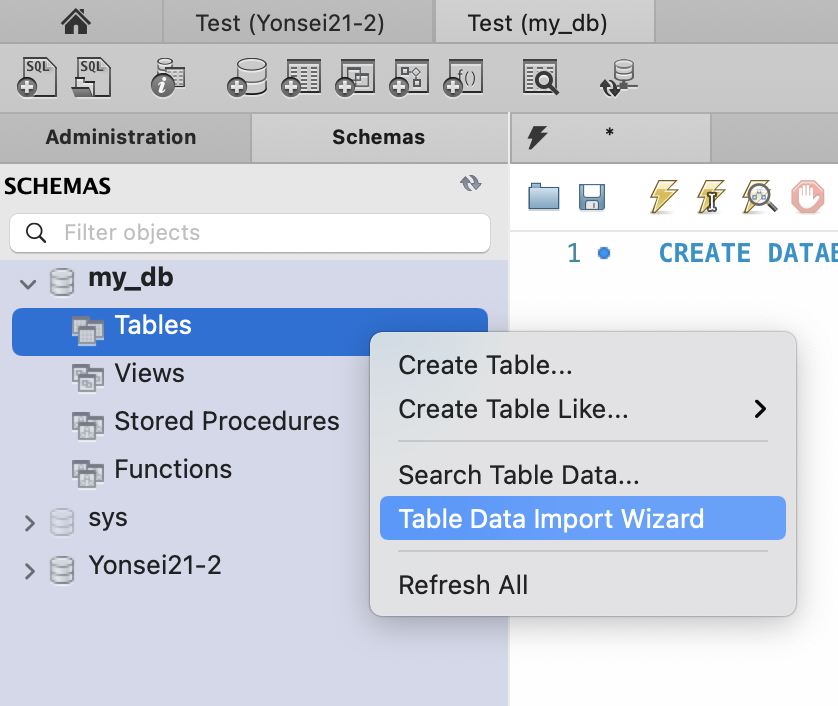
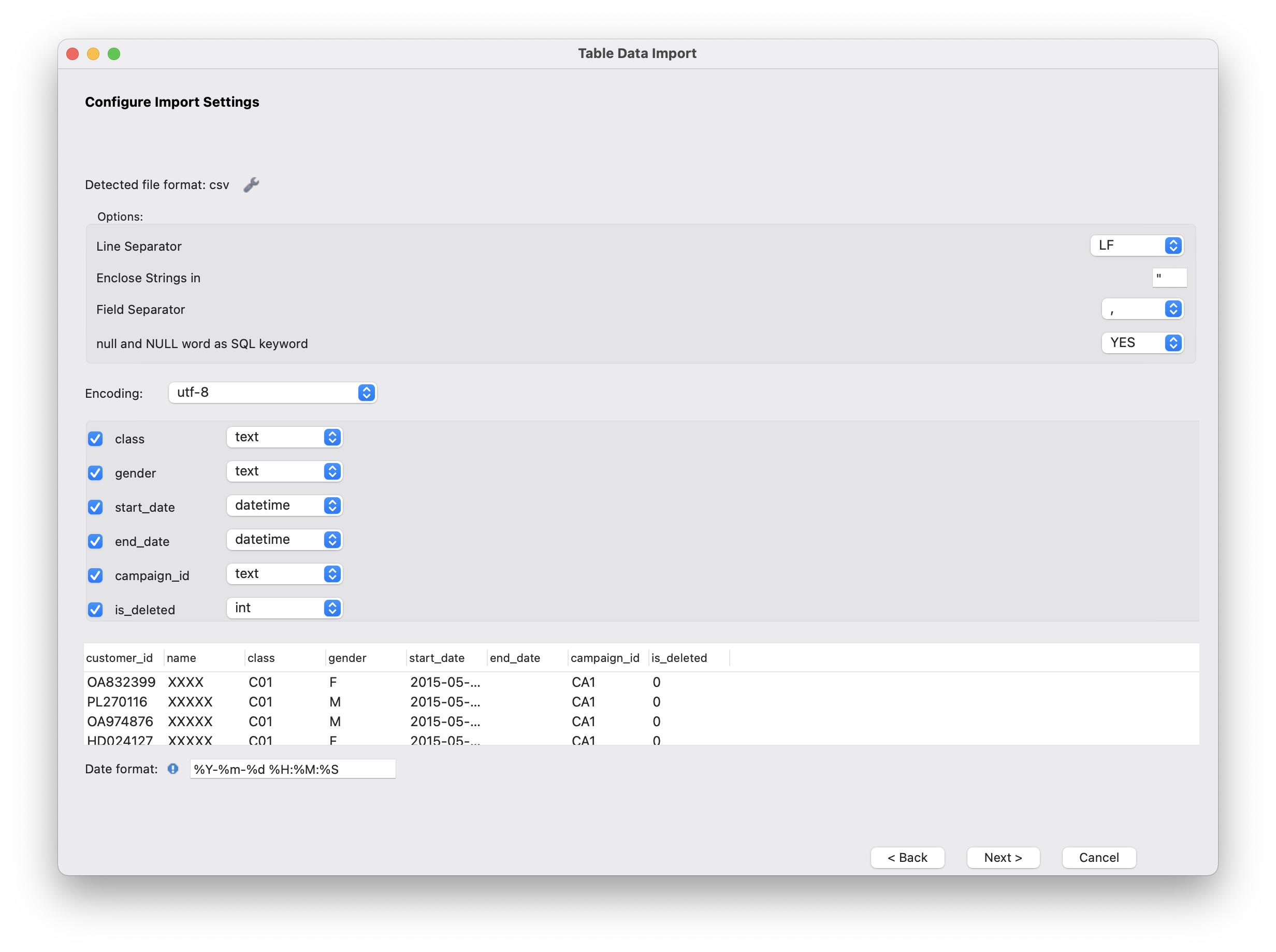
각 칼럼의 자료형과 주어진 데이터의 형식에 맞게 세부적인 사항들을 지정해주자. csv 파일을 불러올 때는 Field Seperator를 콤마로 지정해줘야한다는 점을 명심하자.
성공적으로 데이터가 불러와졌다면, 테이블 명 옆에 있는 차트 모양 아이콘을 클릭해 데이터의 일부를 출력할 수 있다.
이와 동일하게 나머지 데이터들도 불러오자.
데이터 조회
불러온 데이터를 바탕으로 특정한 조건을 만족하는 엔트리들을 조회하는 방법에 대해 알아보자. 기본적인 문법은 다음과 같다.
SELECT (조회할 칼럼명) FROM (DB이름) WHERE (조건);
조회할 칼럼명에 * 를 입력하면 조건에 맞는 데이터셋 전체를 반환하게 된다. 참고로, SQL 문에서는 쿼리의 마지막에 항상 세미콜론 ; 을 붙여줘야 한다.
다음의 SQL문을 실행해 제대로 된 결과가 출력되는지 확인해보자.
- 참고:
LIKE명령어의 인자로 입력되는 문자열에서%는 임의의 길이를 갖는 값을 나타내며,_는 한자리의 임의의 값을 나타낸다.
여러개의 조건
여러개의 조건을 걸어서 데이터를 조회할 수도 있다. 이는 논리연산자인 AND 와 OR 을 사용하면 되는데, AND 가 OR 보다 더 우선적으로 실행된다는 점을 주의하자.
다음은 여러개의 조건이 있는 경우 데이터를 조회하는 SQL문이다.
데이터 정렬
조회된 데이터를 일정한 순서대로 정렬할 수 있다. SQL문에 ORDER BY 명령어를 포함시키면 된다. 이를 포함해서 앞서 작성한 SQL문을 간단하게 수정해보자.
- 참고:
ASC와DESC명령어를 추가해 오름차순과 내림차순을 직접 지정할 수 있다. (디폴트는ASC)
여기에 추가적으로 LIMIT 명령어를 사용하면 정렬된 값중 일부만 출력할 수 있다.
- 참고: SQL은 파이썬과 동일하게 인덱스가 0부터 시작된다.
새로운 변수 추가하기
앞선 내용들을 통해서 SQL문의 작동 원리에 대해 어느정도 감이 잡혔을 것이다.
마지막으로 SQL문을 이용해 주어진 데이터를 가공하는 방법에 대해서 알아보자. 헬스장 회원 데이터에서 현재 등록된 회원들의 등록 기간을 새로운 변수 enrolled_period 로 정의할 것이다.
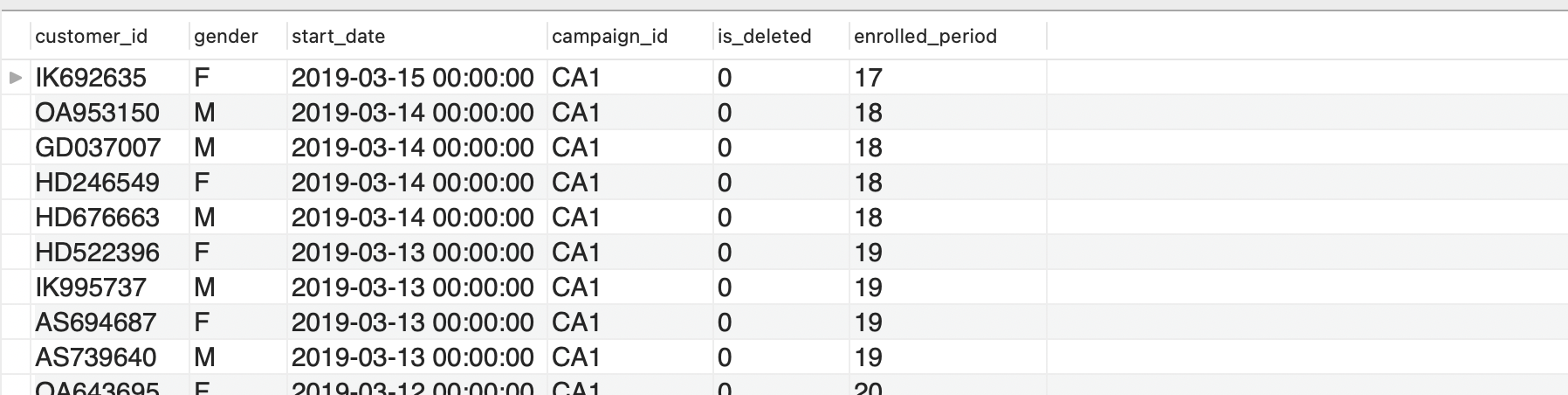
실행 결과
DATEDIFF 함수를 이용해 해당 데이터가 집계된 시점인 2019년 4월 1일로부터 회원들의 등록일을 빼서 새로운 칼럼을 정의한 뒤, 이를 기준으로 데이터셋을 오름차순 정렬했다. 해당 SQL문을 정확하게 이해하고 사용할 수 있다면 이후 살펴볼 좀 더 복잡한 내용도 어렵지 않게 이해할 수 있을 것이다.
다음 포스트에서는 서로 다른 테이블을 하나로 합치는 조인 방법에 대해 살펴볼 예정이다.