Data Analysis in SQL (Part 3)
저번 포스트에서는 헬스장의 회원 정보와 관련된 3개의 테이블을 하나의 테이블로 합치는 SQL에서의 테이블 조인 방법에 대해 다뤘다.
이를 바탕으로, 해당 포스트에서는 본격적인 데이터 분석 단계로 나아가기 위한 준비 단계로 몇가지 함수를 살펴보도록 하겠다.
목차
결측치 처리
(이후의 내용은 모두 저번 포스팅에서 정의한 customer_joined 테이블을 바탕으로 진행된다.)
가장 첫번째로, 결측치를 다루는 방법에 대해서 살펴보자. 주어진 테이블에 결측치가 있는지 확인하는 SQL문은 다음과 같다.
실행 결과
현재 헬스장 데이터셋에는 결측치가 없음을 확인할 수 있다.
근데 약간 이상하다. 왜냐하면 회원들의 탈퇴 일자에 대한 정보를 담고 있는 end_date 칼럼에는 분명히 값이 없는 엔트리들이 많기 때문이다.
MySQL이 해당 엔트리들을 결측치로 인식하지 못하는 이유는 데이터를 불러오는 과정에서 결측치들이 자동으로 빈 문자열 값 "" 으로 대체되었기 때문이다. 이를 해결하기 위해서는 1) 결측치들을 제대로 인식하도록 설정해서 다시 데이터를 불러오는 방법과, 2) 해당 엔트리들을 결측치로 바꿔주는 방법이 있다. 첫 번째 방법은 다시 테이블들을 조인해야되는 번거로움이 있으므로, 두 번째 방법을 이용해서 "" 값들을 결측치 NULL 로 바꿔주도록 하자.
위의 SQL문은 앞으로 자주 사용될 중요한 구문들을 포함하기 때문에 조금 자세하게 뜯어보도록 하겠다.
우선적으로, 지정된 데이터베이스 my_db에 저장되어 있는 customer_joined 테이블을 수정하기 위해 UPDATE ~ SET 문을 사용한다. UPDATE 명령어 뒤에는 수정될 테이블을, SET 명령어는 뒤에는 수정될 칼럼 = 수정할 값 형식으로 값을 설정해주면 되는데, 수정할 값 부분에는 별도로 CASE ~ END 문을 사용해서 조건식을 지정해주었다. (혹여 MySQL에서 safe update 기능이 설정되어 있으면 이런식으로 칼럼 전체를 수정하는 것이 시스템적으로 막혀있을 수 있다. 이 경우 에러 코드를 참고해서 safe update 기능을 해제해주자)
CASE ~ END 문은 SQL에서의 조건문이다. CASE 명령어로 조건문을 시작한 다음, end_date 칼럼에서 엔트리의 값이 "" 인 경우 NULL 값으로 대체하도록 지정했다. 마지막으로 END 명령어를 이용해 해당 조건문을 끝내주면 된다. 앞으로 조건문은 자주 등장할테니 CASE ~ END 형식의 조건문에 익숙해지도록 하자. (조건문 안에서 WHEN 을 여러번 사용하면 더욱 복잡한 조건식도 표현 가능하다.)
어쨌든, 해당 SQL문을 실행한 다음 customer_joined 테이블을 출력해보면 end_date 칼럼에 결측치들이 제대로 추가된 것을 확인할 수 있다.
그럼 이제 본격적으로 결측치를 다뤄보도록 하자.
end_date 칼럼에 결측치가 몇개나 있는지는 다음과 같이 파악할 수 있다.
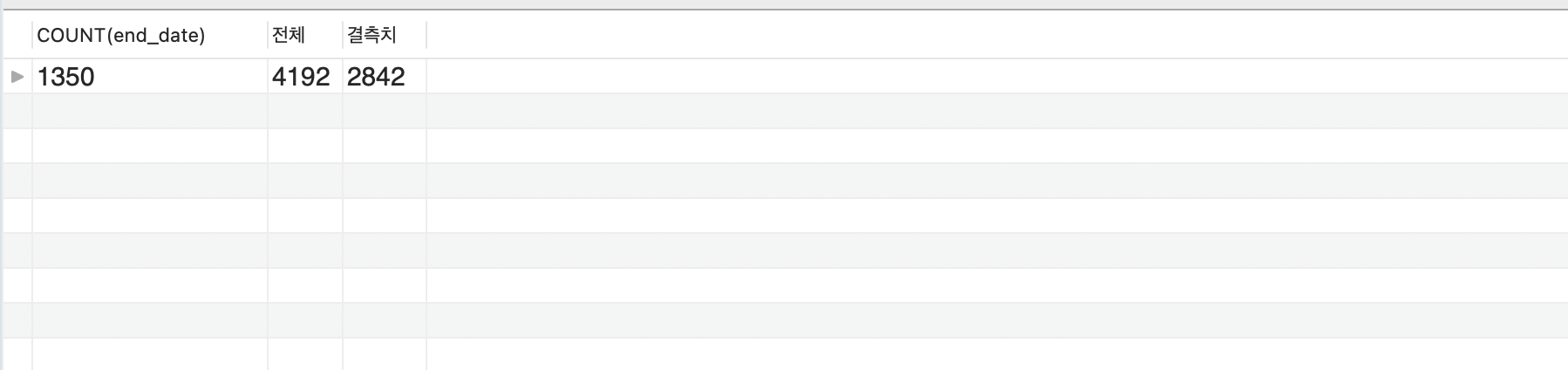
실행 결과
COUNT() 함수는 엔트리 수를 셀 때 결측치를 포함하지 않는다는 점을 이용해서 결측치의 개수를 파악할 수 있다. 탈퇴일자가 결측치인 것은 아직 헬스장에 다니고 있음을 의미하기 때문에 현재 헬스장에 등록된 회원은 1350명 임을 알 수 있다.
앞서 본 것과 같이 SQL에서 NULL 값은 그 자체로 결측치라는 특별한 의미를 갖기 때문에 데이터를 집계하는 과정에서 생략돼버릴 수 있다. 또한 프로그래밍 언어에 익숙하지 않은 사람은 NULL 이 어떤 의미인지를 모를 수도 있기 때문에, 분석의 편의상 해당 결측치들을 다른 문자열로 대체해보자.
MySQL에서 결측치를 다른 값으로 대체하는 가장 간단한 방법은 COALESCE() 함수 또는 IFNULL() 함수를 사용하는 것이다. 또한 앞서 살펴본 조건문을 적절히 활용해서도 가능하다. 다음 SQL문은 end_date 칼럼의 NULL 값을 "N/A" 라는 문자열로 치환하는 서로 다른 4개의 방법을 소개한다.
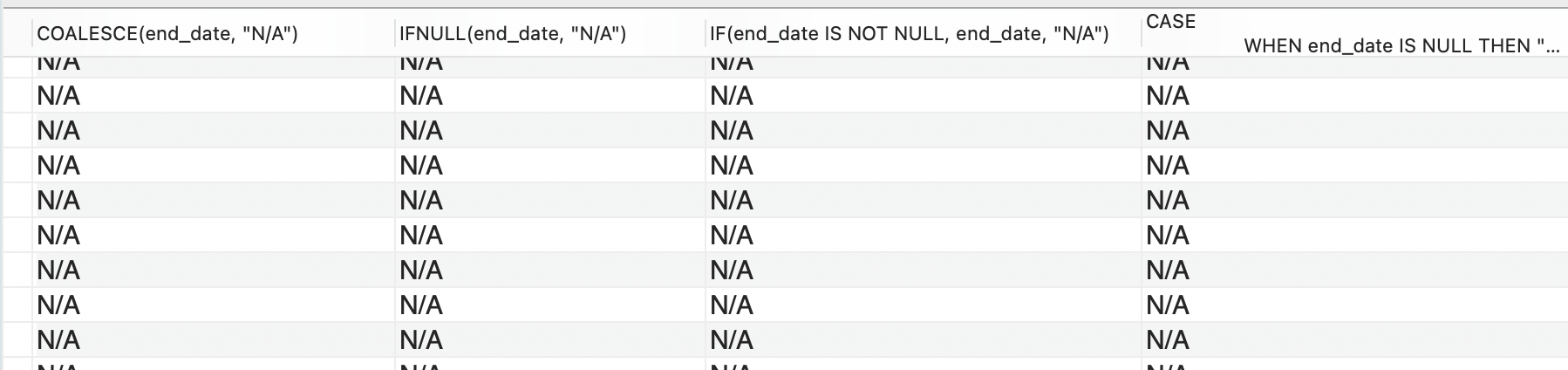
실행 결과
4개의 방법 모두 동일한 결과를 얻을 수 있음을 확인할 수 있다.
- 참고:
COALESCE(칼럼, 결측치가 아닌 경우 대체할 값, 결측치인 경우 대체할 값)와 같이 3개의 인자를 입력해서 사용할 수도 있다.
다음의 코드를 실행해 해당 결과를 customer_joined 테이블에 추가하도록 하자.
기술 통계량
다음으로는 기술통계량을 계산하는 함수들에 대해 살펴보자. 몇가지 기술 통계량을 계산하기 위해 각 회원별로 회원 기간을 계산해 테이블에 추가해주도록 하겠다. MySQL에서 테이블에 새로운 칼럼을 추가하기 위해서는 1) 새로운 칼럼을 정의한 다음, 2) 해당 칼럼에 값을 추가하는 방식으로 쿼리문을 작성해야 한다. 다음은 회원들의 회원 기간을 계산해 enrolled_period 라는 칼럼을 만드는 SQL문이다.
이렇게 정의된 enrolled_period 을 바탕으로 기술통계량들을 계산해보자. 이 부분은 별도의 설명이 필요 없을 것 같아 각 기술통계량을 계산하는 MySQL 함수만 첨부하도록 하겠다.
안타깝게도, MySQL에서는 사분위 수를 직접적으로 계산하는 함수는 별도로 지원하고 있지 않다 (혹시 있으면 알려주세요..). 사분위수는 이후 다룰 서브쿼리문을 이용해서 구할 수 있기는 한데, 굳이 복잡하게 SQL문을 짤 바에는 파이썬이나 R 을 이용해 값들을 확인하는 것이 더 효율적일 것 같다.
추가적으로, SQL에서 산술적인 계산을 위해 사용할 수 있는 집계 함수들 몇개도 위에 적어놨다. 이 밖에 다른 집계 함수들은 해당 사이트 에 정리되어 있으니 참고하면 좋을 것 같다. 이 부분 역시 별도로 설명은 필요하지 않을 것 같으므로 넘어가도록 하겠다.
문자열 처리
파이썬만큼 강력하진 않지만, SQL 역시 문자열을 다루기 위한 몇가지 함수를 제공하고 있다.
우선 첫 번째로 DISTINCT() 함수를 이용해 특정 칼럼에서 고유한 (unique) 값들만을 출력할 수 있다. customer_joined 테이블에 어떤 값들이 있는지를 보고 싶으면 아래의 쿼리문을 실행시키면 된다.
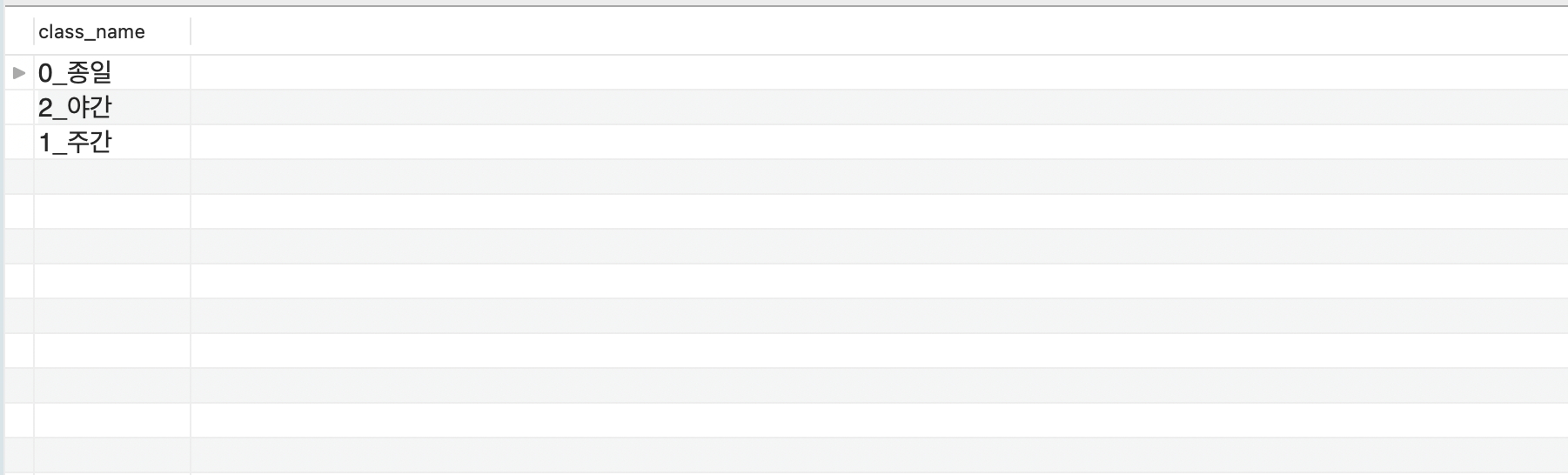
실행 결과
DISTINCT() 함수를 좀 더 응용해보자.
customer_joined 테이블의 고객 ID를 잘 살펴보면, ID의 형식이 \w\w\d\d\d\d\d\d 형식으로 되어 있는 것을 확인할 수 있다. 즉, 고객 ID의 첫 두 글자는 ID를 분류하는 기준이라고 해석할 수 있을 것 같은데, 이러한 맥락에서 고객 ID의 처음 두 글자를 추출하고 싶다고 해보자.
이렇게 특정한 문자열의 서브셋을 반환하려면 SUBSTRING() 함수를 이용하면 된다. 앞서 살펴본 DISTNCT() 함수와 결합해서 고객 ID가 어떻게 구분되어 있는지를 살펴보도록 하겠다. 다음의 SQL문을 실행시켜보자.
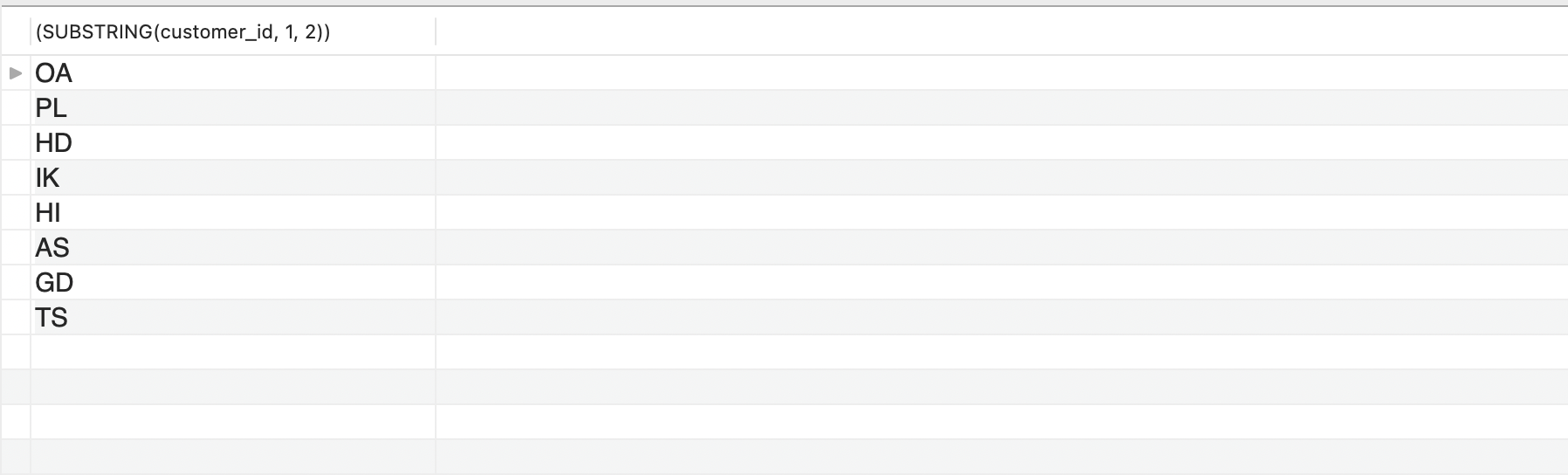
실행 결과
고객의 ID는 총 8가지의 분류로 생성되는 것을 확인할 수 있다.
이 밖에도 문자열을 다루기 위해 알아두면 좋은 함수들 몇가지는 다음과 같다.
LENGTH(문자열): 문자열의 길이를 반환한다.UPPER(문자열)&LOWER(문자열): 문자열이 영어인 경우 대소문자 변환을 위한 함수이다.LPAD(문자열, 패딩길이, 패딩토큰): 특정 문자열의 왼쪽에 패딩을 설정한다. 이와 동일하게 오른쪽에 패딩을 추가하려면RPAD()함수를 사용하면 된다.LTRIM(문자열),RTRIM(문자열),TRIM(문자열): 문자열의 공백을 없앤다. 각각 해당 문자열의 왼쪽, 오른쪽, 전체 공백이 삭제된다.
다음 포스트에서는 그루핑을 이용해 데이터를 분석하는 방법에 대해 알아보겠다.