[Bayesian Statistics] Basis Function Models
Ch 20. Basis Function Models
This post is a summary of Chapter 20 of the textbook Bayesian Data Analysis.
Table of Contents
20.1 Splines and weighted sums of basis functions
20.2 Basis selection and shrinkage of coefficients
20.3 Non-normal models and multivariate regression surfaces
20.0 Nonparametric Models
- Chapter 19 dealt with “parametric” nonlinear models where the function of predictors and parameters were prespecified.
-
In the following chapters, we consider models where the function $\mu$ is also a priori unknown.
- Since we don’t know $\mu$, we have to estimate it somehow.
- There are various ways to model $\mu$ and in this chapter, we consider using basis function expansions.
- The key idea of basis function models is to linearly combine set of simple functions of the predictor variables to approximate arbitrary nonlinear functions.
- Note that above equation reduces to standard linear regression model when $\phi$ is an identity function.
20.1 Splines and weighted sums of basis functions
Basis Function Expansion
Let’s consider a set of nonlinear functions $\mu(\dot)$. We can model this $\mu$ by the basis function expansion such that
where $b$ is a prespecified set of basis functions and $\beta$ is the vector of corresponding basis coefficients.
-
In a nutshell, we are approximating $\mu(x)$ by a linear combination of $H$ different basis functions.
-
A taylor series expansion is a familiar example where the basis functions are polynomials of increasing degree.
Example of Basis Functions
A typically used set of basis functions is the local basis functions that are centered on different locations $x_h$ so that $b_h(x)$ reduces to zero when $x$ is reasonably far away from the center $x_h$.
Here we introduce two often-used family of basis functions which are Gaussian radial basis functions and B-Spline.
- An example of approximating the normal curve by the cubic B-spline basis functions:
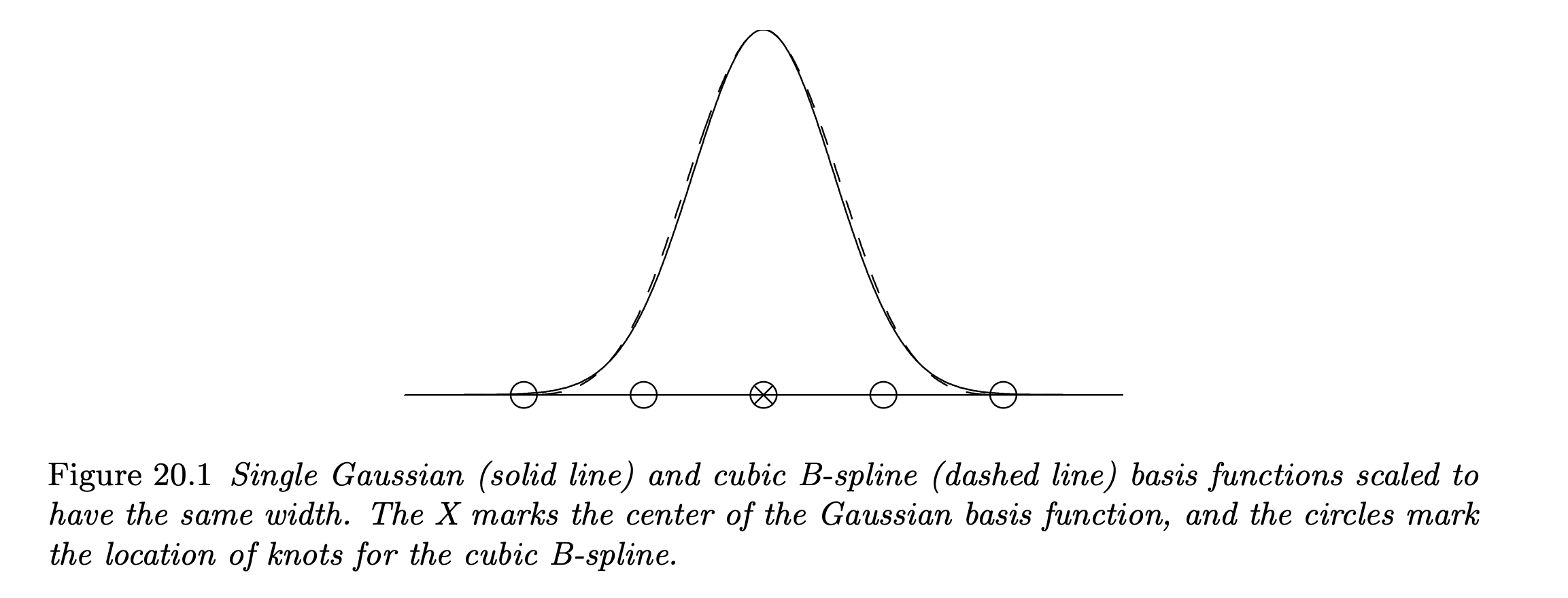
- B-splines have a more complex functional form than Gaussian radial basis functions, but has compact support which leads to sparser design matrix. This can be exploited for enhancing computational efficiencies.
-
Gaussian radial basis function usually produces smoother functions than B-spline as they are infinitely differentiable in the support.
- An example of 4 realizations of prior for a nonparametric function using the cubic B-spline basis functions:
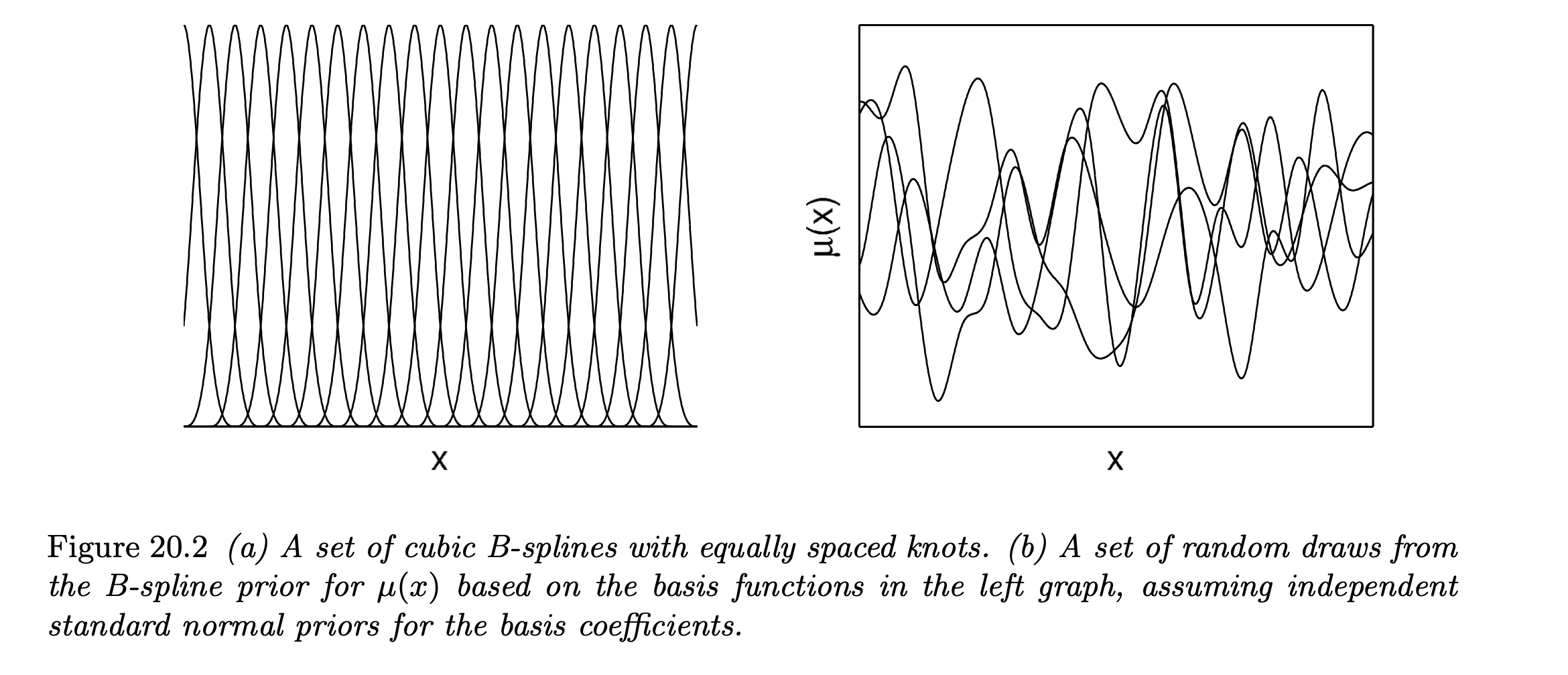
- Note that the number of basis functions (splines) $H$ directly impacts the flexibility of the resulting approximation of a target function.
- In this setting, our model is conditionally linear on the selected basis functions and we can apply the model fitting ideas of standard linear regression like the Least Squares method to estimate the basis coefficients $\beta$.
- An example of estimating the nonlinear curve by B-splines:
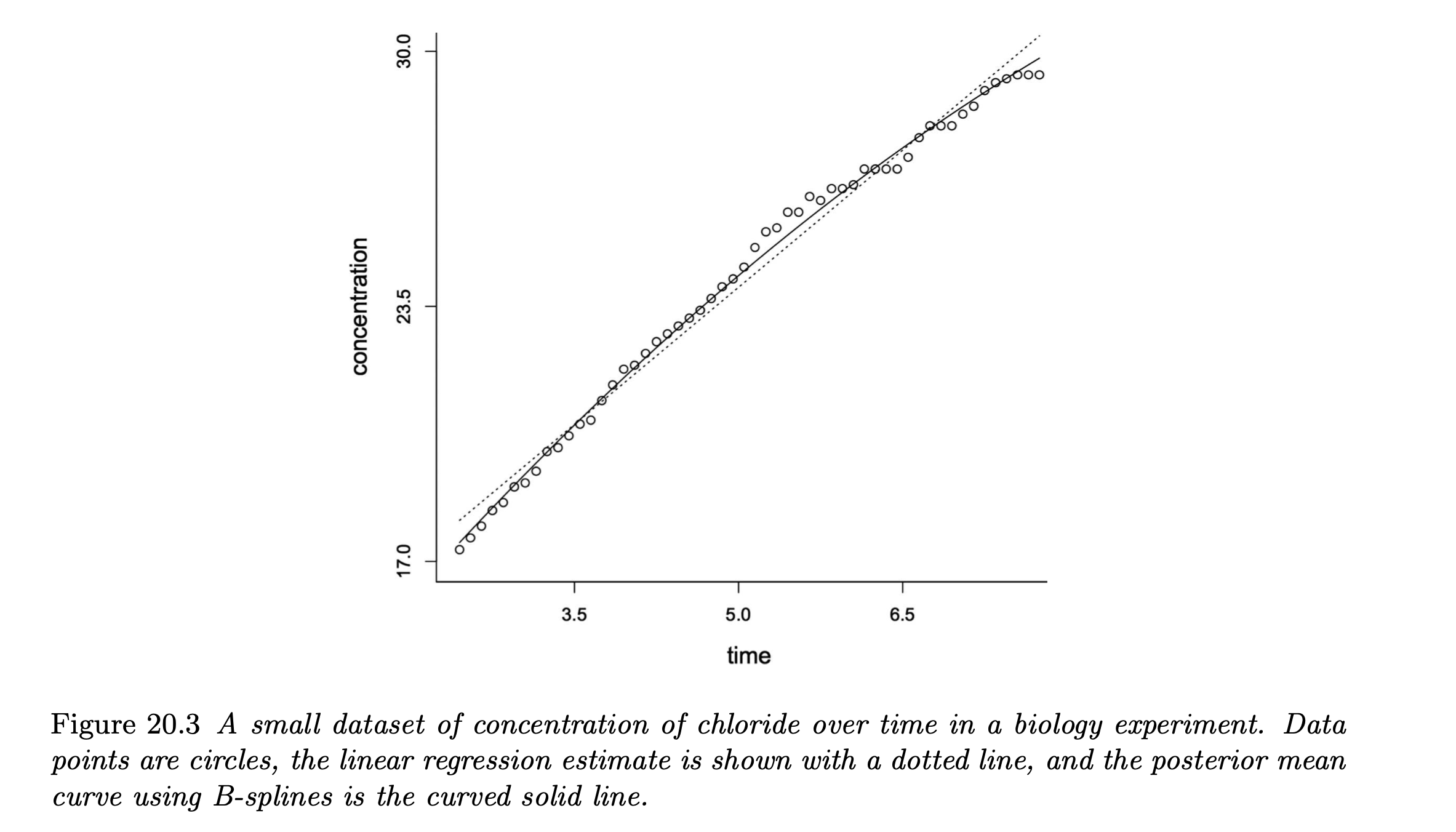
- Note that the posterior mean curve is attained by averaging over the posterior distributions of the basis coefficients for each of the basis functions.
Deciding number of knots for B-splines
In applying splines, we need to specify the number of knots and their locations.
- The most naive approach is to arbitrarily choose sufficient number of knots (no optimization).
- As a Bayesian alternative, we can set priors on the number and locations of each knots which is called as a free knot approach. However, this idea faces computational challenges as it requires highly efficient reversible jump MCMC (between 0/1) for posterior computation.
- Rather, we can select sufficiently many knots and implement variable selection to shrink the coefficients of the less important splines to near zero. This can be done by introducing a shrinkage prior that is concentrated near zero with heavy tails.
20.2 Basis selection and shrinkage of coefficients
Let’s take a closer look at the basis selection by focusing on the single-predictor nonparametric regression model with Gaussian residuals.
- In practice, we are mostly uncertain in which basis functions are really needed.
To allow less important basis functions to naturally be excluded from the model, we introduce an auxilary variable $\gamma$ to denote model index such that:
- $\Gamma$ is a model space containing $2^H$ possibilities for $\gamma$’s.
For a complete Bayesian model specification, we require a prior over the model space $\Gamma$ as well as a prior for the non-zero basis coefficients $\beta_\gamma = \{ \beta_h: \gamma_h = 1 \}$.
- A simple specification is by using the mixture prior such that:
- Hence, each of the basis coefficients will be set to 0 with probability $\pi_h$ (unimportant basis functions) and drawn from the Normal prior otherwise (important basis functions).
- In this prior specification, the joint posterior density for $\gamma$ can be tracked analytically using conjugacy, but the posterior probability for a specific model $\gamma_h$ is intractable since it requires averaging over all potential candidates of $\gamma$ ($2^H$).
-
So we must use approximation such as MCMC-based stochastic search algorithm to identify high posterior probability models in the model space, or Gibbs sampling to iteratively updates $\gamma_h$ from its Bernoulli full conditional posterior.
- Anyways, the key takeaway is that we can potentially conduct model selection to obtain a simplified model without the unnecessary basis functions by averaging the joint posterior $p(y|X, \gamma)$ with respect to $\gamma$.
One possible drawback of this Bayesian variable selection for basis functions is that it might be sensitive to the initial choices of basis functions.
- We can potentially include multiple types of basis functions and implement Bayesian variable selection to find out the subset of basis functions doing the best job at parsimoniously characterizing the curve.
- So whenever possible, prior information should strongly inform the selection of basis functions.
Shrinkage priors
The basis selection method by introducing an auxilary model index variable $\gamma$ is indeed appealing, but it comes with a computational price.
- Since the number of possible models to consider is $2^H$, for sufficiently large number of basis functions, only a small percentage of the whole model space will be visited by our MCMC sampleers even in several hundreds of thousands of iterations.
- This gets even worse for non-conjugate priors.
One possible remedy for this problem is to use shrinkage priors for the coefficients, where the basis coefficients are avoided from being set exactly to zero.
- An appropriate prior for this purpose should have high density at zero, while having heavy tails to avoid over-shrinking the signals of important basis functions.
- The most useful shrinkage priors can be expressed as scale mixtures of Gaussians as follows:
- For choice of the mixture distribution G, we can use several priors such as the Cauchy prior, Laplace (double exponential) prior or the generalized double Pareto prior.
According to the author, the generalized double Pareto prior is specifically mentioned that this distribution can indirectly be sampled by reparamerization of its parameters using Normal, Exponential and Gamma distributions.
- We can use a simple Gibbs sampler to get posterior samples for each of the parameters and basis coefficients (for more detail refer p.494).
- We expect from this generalized double Pareto shrinkage prior to shrink many of the basis coefficients towards zero, while not shrinking the coefficients for the more important bases much at all in high-dimensional settings.
20.3 Non-normal models and multivariate regression surfaces
Non-normal models
We can relax our model to accommodate heavier-tailed residual densities which can handle possible outliers by using a scale mixture of the gaussians.
- One example is the “inverse-gamma scale mixture of normals representation” of the residual density such that:
- Each response has different variance structure and the value of $\phi_i$ will control the scale of the response, downweighting the influence of outliers on the posterior distribution of $\mu(x)$.
- To extend the response distribution to the exponential families, we can use various link functions just like for the GLMs in the same framework as above.
Multivariate regression surfaces
So far, we have focused on regression models with a single predictor. What can we do to incorporate multiple predictors?
For multivariate cases, the curse of dimensionality arises.
- Computational methods that work for small number of predictors may not scale well as predictors are added. This is because the number of basis functions needed increase exponentially with respect to increase in the predictor variables.
- We need sufficiently large number of data points, prior information or some restrictions to reliably estimate a nonparametrical multivariate regression because the observations are sparsely distributed in high dimensional predictor surfaces.
- To account for this, a commonly used assumption is the additivity of the curve function by univariate regression functions:
-
Above, an unknown coefficient function for each of the predictor $\beta_j()$ is expressed as a linear combination of a prespecified set of basis functions $b_j = \{b_{jh} \}_{h=1}^{H_j}$.
-
Additivity assumption might not be plausible when there is interaction effect among the predictor variables. In this case, we can think of using tensor product specification (for more detail refer p.497).
- In addition to additivity assumptions, we can set constraint on shape of the priors to further enhance the efficiency.
- For example, if we are certain that our response is nondecreasing in some of the predictors, we can set nondecreasing constraint on certain $\beta_j(x_j)$ in the additive expansion. Let’s check this by an example.
Example. A nonparametric regression function that is constrained to be nondecreasing
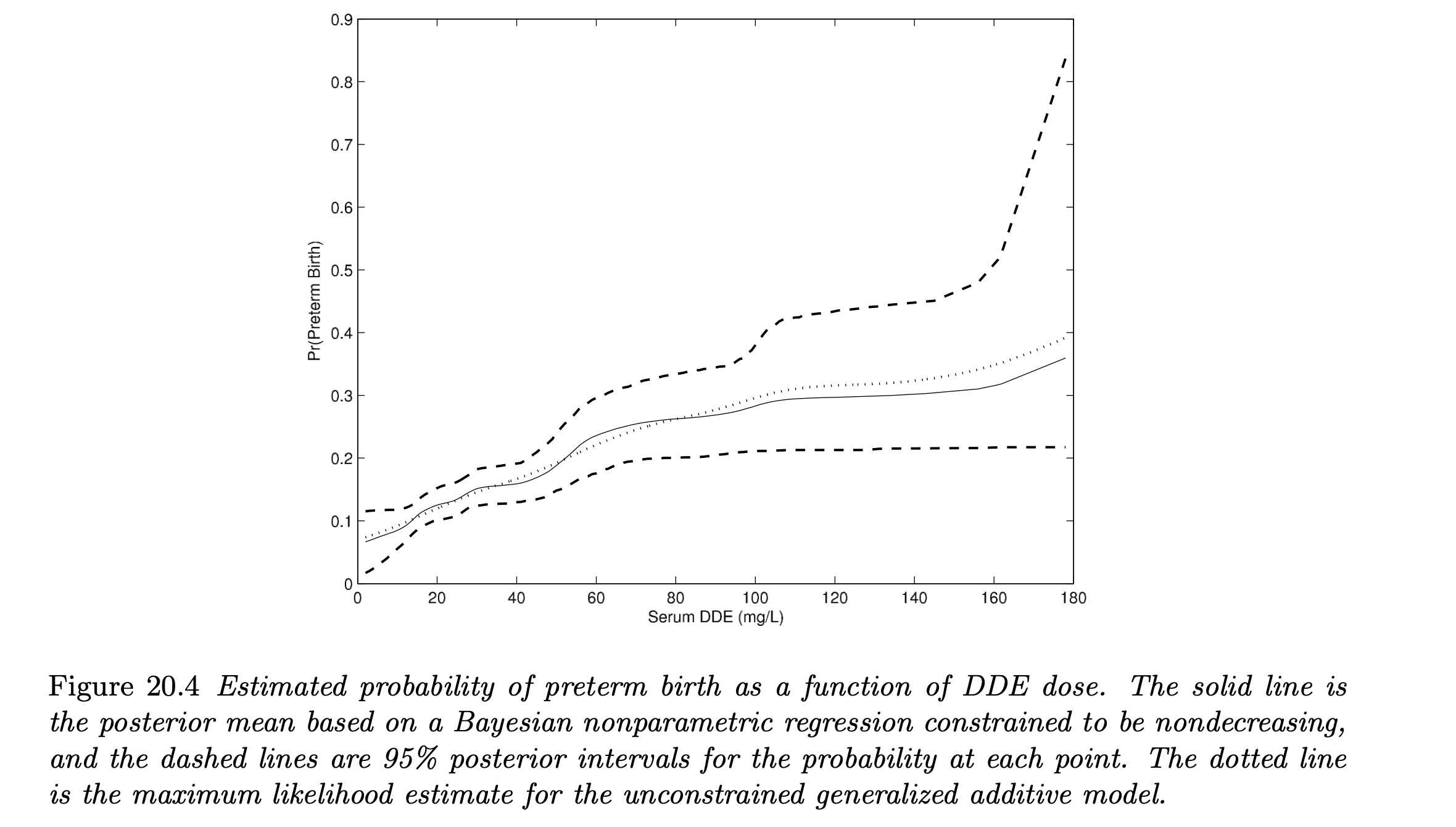
We consider an example of pregnant women data in the U.S. Collaborative Perinatal Project, where the incidence of “preterm birth” is studied in relationship with 5 different covariates (cholesterol, triglyceride level, age, BMI, smoking status) and “DDE concentration” (DDE is a persistent metabolite of the pesticide DDT).
Let’s see how we can incorporate a nondecreasing constraint on the regression function relating level of DDE to the probability of preterm birth.
- This constraint is made because we have a reasonable “a-priori belief” that covariate-adjusted premature delivery risk is nondecreasing in dose of DDE.
We use semiparametric probit additive model such that:
-
The covariate adjustments are parametric (although not described), while $f(x)$ is characterized nonparametrically as a nondecreasing curve using splines with a carefully structured prior on the basis coefficients. The basis functions are simply piecewise linear functions with a dense set of knots.
-
To incorporate the constraint, we choose a prior for the basis coefficients that does not allow negative values. Since these coefficients are directly the slopes of the regression lines at each knots, the resulting nonparametric curve cannot be decreasing.
-
For the (latent) basis coefficients, we use first-order normal random walk autoregressive prior such that:
- Note that $\delta$ is a positive threshold parameter which links latent $\beta_j^*$ to the slopes $\beta_j$.
- By implementing an MCMC algorithm for posterior computation, we get the following estimated curve $f(x)$:
References
- Gelman et. al. 2013. Bayesian Data Analysis. 3rd ed. CRC Press. p.487-498.