[A/B Test] 데이터 수집과 인과관계
해당 포스트를 시작으로 A/B Test를 설계 및 진행함에 있어 필요한 통계학의 기초적인 개념들을 간단하게 리뷰하는 시간을 가져보려고 한다. 사실 통계학의 내용들이 휘발성이 강한 측면이 있기 때문에 세세한 수식 보다는 전공자로서 공부를 하면서 느꼈던 점들을 직관적인 아이디어 위주로 정리할 예정이다.
1. 결국 시작은 데이터이다.
통계학은 데이터를 바탕으로 의사결정을 내리는 학문이다. 이전 포스트들에서 이미 다룬적이 있지만, 통계학에서 다루는 작업의 범주는 크게 “추정”, “검정”, “예측“의 세가지 범주로 분류될 수 있는데, 학부 수준의 통계학 수업들에서는 주어진 데이터를 요리조리 잘 사용해서 관측되지 않은 모수 (parameter) 를 추론하는 과정에 대해 공부한다.
하지만 이 과정에서 크게 등한시되는 부분은 바로 “데이터” 그 자체라고 생각한다. 우리가 통계학을 공부하는 대부분의 상황들에서는 데이터가 이미 주어졌다는 가정하에 논의가 이루어진다. 예를 들어, 수리통계학에서 등장하는 단골 문제 중 하나는 데이터 $X_1, \dots, X_n$이 주어졌을 때, 이를 바탕으로 MLE를 구하거나 MVUE 등을 구하는 식의 문제이다.
이러한 맥락에서 대학원 생활을 하면서 느꼈던 큰 부분 중에 하나는 종종 연구의 성과에 있어서 복잡하고 발전된 모델을 사용하려는 노력보다 어떻게 하면 양질의 데이터를 사용할 수 있을지에 대한 고민이 훨씬 유효한 경우가 있다는 점이다. 돌이켜보니 이러한 이유로 석사 과정의 연구 분야를 아웃라이어 탐지 쪽으로 잡은 것도 없잖아 있는 것 같다.
예전에 수업을 수강했던 어떤 교수님께서는 통계학자를 종종 요리사에 비유하고는 하셨다. 요리사가 음식을 만드려고 하는데 주어진 식재료가 전부 상했다면 제 아무리 백종원이라도 퀄리티 좋은 음식을 만들기는 어려울 것이다. 또한 아무리 극상의 식재료가 있다 하더라도, 식재료 각각에 맞는 전처리 과정을 거치지 않으면 그 자체로는 아무런 의미가 없을 것은 자명하다.
마찬가지로 통계학은 무에서 유를 창조하는 학문이 아니기에, 통계학을 제대로 공부한 사람이라면 “데이터 수집“이라는 첫 단추를 잘 끼워 넣는데에 충분한 시간을 할애해야 한다. 그렇다면 본격적으로 인과관계의 측면에서 다시 한번 데이터 수집이 왜 중요한지에 대해 살펴보도록 하겠다.
2. 데이터를 수집하는 방법: 관찰 연구 vs 실험 연구
통계적 의사결정 과정은 데이터를 수집하는 방법에 따라 크게 “관찰 연구“와 “실험 연구” 두 가지로 구분할 수 있다.
첫 번째로 관찰 연구란, 수집될 데이터에 영향을 미칠 수 있을 것이라고 생각되는 여러 변수들을 연구자가 의도적으로 조작할 수 없는 경우를 의미한다.
간단한 예시를 살펴보자. 가령 어떤 모바일 앱의 새로운 UI가 더 많은 매출을 가져올 수 있을지에 대해 관심이 있다고 가정해보자. 이를 판단하기 위해 새로운 UI를 적용하기 전/후의 매출에 대해 각각 유저들로부터 데이터를 수집한 뒤, 그 평균의 차이를 비교해보았다. 그 결과, 새로운 UI를 적용한 뒤에 평균적으로 약 10% 정도 매출이 증가했다는 사실이 확인되었다.
그렇다면 이 경우, “새로운 UI의 도입이 매출의 상승으로 이어졌다!” 라는 결론을 내릴 수 있을까? 결론부터 말하자면, 꼭 그렇지만은 않다. 예를 들어, 매출이 증가한 이유가 UI의 변화 때문이 아니라 코로나의 영향으로 인해 언택트 생활이 보편화되면서 단순히 앱 사용자의 절대적 숫자가 늘어났기 때문일 수 있다. 또는 새로운 UI를 사용한 유저들이 원래부터 앱을 많이 사용하는 충성 고객일 수도 있다.
이와 같이 데이터가 수집되는 과정에서 연구자가 아무런 개입을 하지 않는 것이 관찰 연구이다, 뒤에 다시 살펴보겠지만, 관찰 연구를 바탕으로 얻어진 결론에서는 절대로 인과 관계 (ex. A이면 B이다) 를 주장할 수 없다.
자 그럼 다음으로 실험 연구에 대해 살펴보자. 실험 연구는 관찰 연구와는 반대로, 연구자가 데이터의 수집 과정에 적극적으로 개입해서 관심 변수에 영향을 미칠 것이라고 생각되는 모든 변수들의 효과를 일정한 수준으로 컨트롤 하는 것을 의미한다.
앞선 예시를 다시 살펴보자면, 만약 “매출”이라는 관심 변수에 대해 “새로운 UI”만의 순수한 영향력을 파악하기 위해서 나이, 시간 등 다른 모든 잠재적인 변수들을 동일한 수준으로 관리하는 경우가 이에 해당된다. 이렇게 진행된 실험 연구의 가장 큰 장점은 바로 인과 관계를 주장할 수 있다는 점이라고 할 수 있는데, 검증하고자 하는 변수를 제외한 나머지 모든 변수들의 효과들이 전부 동일하게 맞춰졌기 때문에 “새로운 UI의 도입이 원인이 되어 10%의 매출 상승이 나타났다!” 와 같은 인과적인 결론을 내릴 수 있게 되는 것이다.
하지만, 사실 실험자가 의도적으로 모든 변수들을 동일한 수준으로 맞춰주는 것은 현실적으로 불가능하다. 실제로 어떤 변수들이 관심 변수에 영향을 미칠 것인지를 사전에 전부 알고 있는 것은 말이 안되고, 특히 IT 회사처럼 서비스의 대상이 유저들인 경우 더더욱 그럴 것이다.
허나 그럼에도 불구하고 우리는 많은 경우 인과적인 결론을 (causal statement) 내리기를 원한다. 그렇다면 이는 정녕 불가능한 것일까? 그렇지 않다. 우리에게는 “무작위 배정 (random assignment)” 이라는 간단하지만 아주 강력한 무기가 있기 때문이다.
3. 무작위 배정은 인과 관계를 보장한다.
앞서 실험 연구는 인과관계를 보장한다는 것을 살펴보았다. 하지만 현실적으로 연구의 결과에 영향을 미칠 것이라고 생각되는 모든 변수들을 통제하는 것은 불가능에 가깝기에, 우리는 이에 대한 대안으로 실험 단위들에 대한 무작위 배정을 사용하게 된다. 참고로 이러한 외부 변수들을 통계학에서는 잠복 변수 (lurking variable) 또는 공변량 (covariate) 라고 부른다.
이와 관련해서 한 가지 첨언하자면, 우리는 절대로 개별적인 관측치에 대한 인과 관계는 파악할 수 없으나, 무작위 배정을 사용하면 모집단 수준에서의 인과 관계는 정확하게 도출할 수 있다. 해당 내용은 이후 인과적 추론 모형과 관련한 포스트에서 다시 다룰 예정이니 지금은 이런게 있다는 정도만 참고하고 넘어가도록 하자.
한 마디로 정리하자면, 말 그대로 “무작위” 배정이란 데이터를 수집할 대상들을 완벽하게 랜덤하게 “실험 집단”과 “비교 집단”으로 분류하는 것을 의미한다. (온라인) A/B Test의 맥락에서 살펴보자면, 앞선 예시에서 모바일 앱에 접속하는 유저들 각각에 대해 50%의 확률로 새로운 UI를 보여줄지 (실험 집단), 아니면 기존의 UI를 보여줄지 (비교 집단) 를 결정하고, 이에 따라 데이터를 수집하는 것이다.
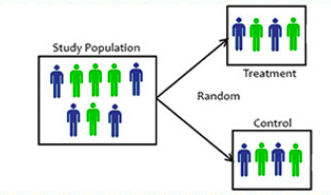
무작위 배정 예시
언뜻 보면 이게 무슨 대수냐고 생각할 수 있으나, 놀랍게도 이렇게 수집된 데이터에서는 우리가 평가하고자 하는 관심 변수를 제외한 나머지 모든 잠복 변수들의 효과가 일정한 수준으로 맞춰지게 된다 (!!). 이에 대한 수식적인 증명은 추후 인과적 추론과 관련한 포스트에서 다룰 예정이니 참고바란다.
이러한 무작위 배정의 아이디어는 인과 관계를 증명하는 것이 무엇보다도 중요한 의학/임상 통계학 분야에서 상당히 많이 사용되는데, 어떤 논문의 abstract 부분에 “randomized controlled ~ “ 이 적혀 있으면 무작위 배정을 바탕으로 데이터가 수집된 실험 연구라고 파악하면 된다. 그리고 이러한 실험 연구에서는 (근사적으로) 인과관계를 주장하는 것이 통계적으로 타당하다고 여겨진다.
4. A/B Test에서의 데이터 수집
앞서 살펴본 모든 내용들은 온라인 환경에서 진행되는 A/B Test 에서도 동일하게 적용되는 개념들이다. 그렇기 때문에 유저들을 랜덤하게 서로 다른 집단에 배정하는 것이 실험의 결과를 해석하는 과정에서 인과 관계를 주장하기 위한 이론적인 기반을 제공하는 것이라고 이해할 수 있다.
물론 무작위 배정을 진행했다고 하더라도 여러 문제가 발생할 수 있다. 가령, 관심 지표가 수집 시점의 영향을 받는 time-sensitive한 데이터인 경우라던지, 그룹 간 샘플 개수의 차이가 커 검정통계량의 수렴 정도 다르다던지 등의 추가적인 문제점이 있을 수 있을 것이다. 이렇게 발생할 수 있는 문제점들을 하나하나 뜯어보며 원인을 파악하는 것은 상당한 인내심을 요구한다.
정리하자면, A/B Test 를 통해서 객관적이고 정확한 결론을 도출하기 위해서는 실험을 설계하는 과정에서 어떻게 하면 양질의 데이터를 수집할 수 있을지에 대해서 많은 고민과 노력이 필요하다. Online A/B Test의 분명한 특징이자 장점 중 하나는 전통적인 임상 시험에 비해 샘플 사이즈가 매우 크다는 점이지만, 그럼에도 불구하고 데이터 자체에서 발생한 bias는 제 아무리 빅데이터라 하더라도 해결할 수 없기 때문에 데이터 수집 과정이 중요하다는 점을 다시 한번 강조드리며 해당 포스트를 마무리하겠다.