[A/B Test] 관찰 연구에서의 인과적 추론 (Observational Causal Studies)
A/B Test는 실험하고자 하는 기능에 대한 인과적인 효과를 파악하기 위해서 수행된다.
>> e.g. 결제 버튼의 폰트 색깔을 검정색에서 회색으로 바꾸었을 때 전환율이 $x$%만큼 증가 / 감소.
그리고 이를 가능케 하는 이론적 배경은 바로 무작위 배정 (randomization) 이며, A/B Test에서 해당 개념의 중요성은 아무리 강조해도 충분치 않다.
A/B Test가 진행되는 과정에서 유저들은 시험군과 대조군에 완벽하게 랜덤하게 배정된다. 비록 사소해보일 수 있으나, 이로 인해 두 실험 그룹의 유저들은 실험하고자 하는 기능을 제외한 나머지 모든 요인들이 동일한 수준으로 통일된다 (추후 구체적인 수식을 통해서 다시 살펴볼 예정이다). 따라서 무작위 배정이 수행된 A/B Test를 바탕으로 얻은 결과에서 결과변수가 $x$ 만큼 변했다는 것은, 우리가 실험하고자 하는 기능이 바로 그 $x$ 만큼의 변화를 발생시킨 “원인”이라는 것과 일맥상통하게 된다.
이렇게 무작위 배정을 통해 수집된 데이터를 바탕으로 결론을 도출하는 일련의 절차를 통계학에서는 “실험 연구”라고 하며, 실험 연구는 인과적인 결론을 도출하기 위한 유일한 방법으로 여겨진다.
그럼에도 불구하고, 현실적인 이유들로 인해 무작위 배정을 진행하기가 어려운 경우 역시 많을 수 있다.
-
항암제에 대한 3상 임상 시험에서, 무작위 배정을 바탕으로 대조군에 배정된 환자에게 위약 (placebo) 을 투약하는 것은 윤리적인 이유로 불가능하다.
-
결과 변수를 통제할 수 없는 경우가 있다 (e.g. user behaviour)
-
구글의 검색엔진에서 광고를 제거하는 것처럼 대조군을 설정하기 위한 비용이 너무 큰 경우가 있다.
이러한 상황들에서 수집되는 데이터는 여러 외부 요인들의 영향력이 공평한 수준으로 보정되지 않았기 때문에, 실험의 결과에서 인과성을 주장할 수 없다. 이처럼 실험 연구와는 반대로 무작위 배정이 수행되지 않은 데이터를 바탕으로 결론을 도출하는 연구를 통계학에서는 “관찰 연구 (observation studies)” 라고 표현한다.
그렇다면 여러 이유들로 인해 무작위 배정이 이뤄지지 않은 관찰 연구의 데이터로부터 인과적인 결론을 도출할 수 있는 방법은 없을까?
이러한 물음에 대한 탐구로, 해당 포스트에서는 observational causal inference (인과적 추론) 라는 통계학의 한 분야를 살펴볼 예정이다. 해당 분야의 선구자는 하버드 대학교의 Donald Rubin 교수인데, 그는 다소 추상적이고 애매모호했던 “인과성”의 개념을 수학적으로 명확히 정립하고, 이를 바탕으로 성향점수분석 (Propensity Score Analysis) 이라는 방법론을 개발한 것으로 유명하다. 2022년 7월 기준으로 그의 논문의 피인용수가 32,000 건을 넘어간다는 점은 해당 연구가 사회과학 전반에 걸쳐 얼마나 큰 영향력을 가졌는지를 여실히 보여준다.
인과적 추론을 위한 통계 방법론의 핵심은 결국 관찰 연구 데이터로부터 “인과성”을 발견하는 것이다. 그리고 이를 위해서는 여러 가정 사항들이 필요하다. 당연히 공짜 점심은 없기 때문에, 무작위 배정이 수행되지 않은 것을 보정하기 위해 필요한 가정들은 다소 비현실적 측면이 있다 (추후에 구체적으로 살펴보겠다). 그래서 이러한 방법론들을 비판하는 사람들도 많은데, 필자도 개인적으로는 이러한 방법론들이 분명한 한계점을 갖고 있다고 생각한다.
그럼에도 불구하고 인과적 추론의 프레임워크를 이해하는 것은 A/B Test를 설계하고 결과를 분석함에 있어서 식견을 넓힐 수 있는 좋은 기회라고 생각한다. 이러한 맥락에서 해당 포스트에서는 인과적 추론을 이해하기 위한 기본적인 개념들과 프레임워크, 그리고 이를 바탕으로 Rubin이 제안한 성향 점수 분석에 대해 대략적으로 살펴볼 예정이다.
1. Counterfactual Model
우선 가장 먼저 Rubin 교수가 제시한 인과 관계를 이론적으로 정의하는 프레임워크를 간략히 소개하겠다.
구체적으로, 여기서는 그가 제안한 “counterfactual outcome“이라는 개념을 응용해서 인과 관계에 대한 분석을 수행하는 과정을 살펴볼텐데, 이를 위해 사용될 몇가지 용어들을 먼저 정의하도록 하겠다.
1. 실험 집단 (treatment group)
- 원인이 되는 사건 (i.e. 실험하고자 하는 기능) 에 “노출된” 유저들을 의미한다.
2. 대조 집단 (control group)
- 원인이 되는 사건 (i.e. 실험하고자 하는 기능) 에 “노출되지 않은” 유저들을 의미한다.
3. 원인 변수
- 알아내고자 하는 인과 관계에서 “원인”이 되는 사건의 발생 여부를 나타내는 변수를 의미한다.
- A/B Test의 맥락에서 이는 대조군 또는 시험군으로의 배정 여부를 의미한다.
- 물론 시험군이 여러개인 경우로 확장 가능하지만, 여기서는 설명의 편의를 위해 control과 treatment 두개의 그룹만을 고려한다.
4. 결과 변수
- 알아내고자 하는 인과 관계에서 “결과”가 되는 사건의 발생 여부를 나타내는 변수를 의미한다.
- A/B Test의 맥락에서 이는 1차 유효성 평가변수(primary metric)을 의미한다.
이를 바탕으로, 우리가 알아내고자 하는 것은 어떠한 실험에서의 원인 변수와 결과 변수간의 인과 관계이다.
이제 설명의 편의상 구체적인 예시로 원인 변수를 “추천 시스템 (A, B)”, 결과 변수를 “평균 매출액”이라고 가정하겠다. 이러한 맥락에서 두 변수간 인과 관계를 가장 정확하게 파악하는 방법은 실험에 참여한 각 유저마다 동일한 시점에서 추천 시스템 A에 노출되었을 때의 매출액과, 추천 시스템 B에 노출되었을 때의 평균 매출액 각각을 측정한 다음 두 값의 차이를 계산하는 것이다 (일반적인 A/B Test).
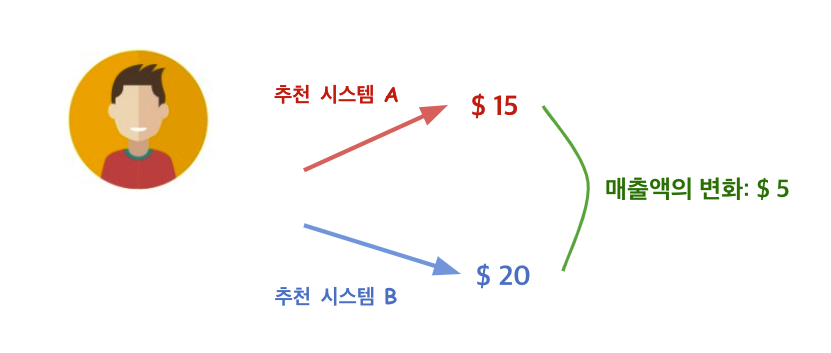
하지만 당연하게도, 완벽히 동일한 시점에서 어떠한 유저를 동시에 서로 다른 추천 시스템 A와 B 각각에 노출시키는 것은 물리적으로 불가능할 것이다. 그렇기 때문에 우리는 결국 유저 레벨에서 인과 관계를 추론하는 것은 불가능하다는 결론에 다다르게 된다.
분명히 앞서 무작위 배정을 이용한 A/B Test에서는 인과 관계를 도출할 수 있다고 했는데, 갑자기 무슨 뚱딴지같은 소리를 하냐는 의문이 들 수 있다. 이와 관련해서, 비록 우리는 개별적인 유저 레벨에서의 인과 관계는 절대로 알 수 없지만 무작위 배정을 사용하게 되는 경우 모집단 레벨에서의 인과 관계는 정확히 도출할 수 있다. 이를 좀 더 구체적으로 살펴보자.
1.1. Counterfactual Model (Rubin Causal Model)
앞서 살펴본 내용을 Rubin 교수가 제안한 방식대로 수식을 도입해서 정의해보도록 하겠다.
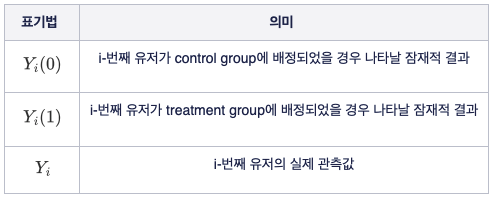
위 표에서 $Y_i(0)$와 $Y_i(1)$을 “counterfactuals”, 혹은 “potential outcomes” 라고 부르며 여기서는 편의상 “잠재적 결과” 정도로 의역해서 사용하도록 하겠다.
여기서 핵심은 어떠한 유저의 잠재적 결과들은 절대로 두 값을 동시에 관찰할 수 없다는 점이다. 그리고 실제 관측값 $Y_i$ 는 잠재적 결과들 중 하나와 완벽하게 일치하는 것이 당연하다.
앞서 언급한 예시에서 유저들에 대한 (가상의) 잠재적 결과는 다음과 같을 수 있다.

이러한 맥락에서 우리는 잠재적 결과와 실제 관측값의 관계를 다음과 같이 수학적으로 정의할 수 있다.
여기서 새로운 변수 $Z_i$ 는 $i$ 번째 유저가 대조군로의 배정될 시 $0$, 시험군으로 배정될 시 $1$의 값을 갖는 더미 변수이다.
자 그렇다면 이를 바탕으로 우리가 추정하고 싶은 인과 관계를 수식적으로 정의해보자. $i$ 번째 유저에 대해 새로운 추천 시스템 B의 매출액에 대한 효과 $\Delta$ 는 다음과 같이 정의된다.
이는 지극히 당연한 내용인데, 두 잠재적 결과의 차이를 발생시키는 원인은 어떤 추천 시스템을 적용했는지에 대한 여부 밖에 없기 때문에 위 식에서의 $\Delta$가 바로 우리가 구하고자 하는 인과 관계라는 것을 쉽게 이해할 수 있다.
앞서 살펴본 예시를 바탕으로 $\Delta$의 구체적인 값을 계산하면 다음과 같을 수 있다.

결론적으로 만약 위 예시처럼 $\Delta$의 값들이 양수일 경우 새로운 추천 시스템 B를 도입하는 것이 효과가 있었다고 주장할 수 있을 것이다.
하지만 앞서 살펴본 것처럼, 두 잠재적 결과를 동시에 관측하는 것은 불가능하기 때문에 우리는 $\Delta$의 값을 직접적으로 추정할 수 없다. 여기에서 델타를 “직접” 추정한다는 것은, 개별적인 유저 레벨에서 인과 관계를 도출하려는 것을 의미한다.
한편, 이제부터 살펴볼 내용은 바로 “모집단” 수준에서의 인과 관계를 알아내는 것은 가능하다는 내용이다. 모집단 수준에서의 인과 관계란, 앞서 살펴본 델타의 “평균”을 추정하고자 하는 것과 일맥상통하다.
이제 구체적으로 위 기댓값이 계산되는 과정을 1) 무작위 배정이 이뤄졌을 때와 2) 무작위 배정이 이뤄지지 않았을 때의 두가지 측면에서 살펴보겠다. 이를 통해서 A/B Test에서 무작위 배정이 왜 그렇게 중요한지를 다시 한번 체감할 수 있을 것이다.
1.2. Randomization: The Gold Standard
위 내용을 바탕으로 무작위 배정이 이뤄졌다는 가정 하에 인과 관계를 의미하는 $\Delta$에 대한 기댓값을 구체적으로 계산해보자.
우선 결과 변수에 영향을 미칠 수 있는 모든 외부 변수들을 $\mathbf{X}$ 라는 변수로 정의하겠다. 이러한 외부 변수들을 인과적 추론 모형에서는 교란 변수 (confounders) 라고 표현한다. 그리고 이러한 교란 변수들은 직접적으로 관찰되기 전까지는 그 값을 알 수 없으므로 확률 변수 (random variable) 로 취급하는 것이 자연스럽다.
자 이러한 상황에서, 만약 $i$ 번째 유저가 대조군 또는 시험군으로 “무작위 배정”될 경우 어떤 일이 발생하는지를 살펴보자. 당연하게도, 무작위 배정이 이뤄졌기 때문에 특정한 유저가 대조군 또는 시험군에 배정되는 사건 $Z_i$는, 각 유저들의 잠재적 결과 $Y_i(0), Y_i(1)$와 아무런 연관이 없을 것이다. 가령, 대조군에 배정되었다고 해서 매출액이 줄어들거나, 또는 시험군에 배정되었다고 해서 매출액이 오르는 등의 일은 벌어지지 않는다. 다시 말해, 확률 변수 $Z_i$ 와 $Y_i$ 는 서로 독립이다.
이를 바탕으로 앞서 살펴본 인과 관계 $\Delta$에 대한 기댓값을 구해보자.
위 전개 과정에서 마지막 등식이 성립하는 이유는, 확률 변수 $Y_i$ 의 정의상 (아래 참고) 대조군 또는 시험군으로의 배정이 되었을 경우 (i.e. $Z_i$ 의 값이 구체적으로 정해지는 경우), $i$ 번째 유저의 잠재적 결과 중 어떤 것이 실제로 관측되었는지가 명확하게 정의되기 때문이다.
따라서 결론적으로, $\Delta$에 대한 기댓값은 다음과 같이 정의된다.
정리하자면, 무작위 배정이 수행되었을 경우 인과 관계 $\Delta$에 대한 모집단 수준에서의 기댓값은 단순히 시험군과 대조군 간의 표본 평균의 차이로 계산되는 것을 수학적으로 도출한 것이다.
따라서 (일반적인) 무작위 배정이 이뤄진 A/B Test에서는 원인 변수와 결과 변수에 대한 명확한 인과 관계를 추론하는 것이 가능하게 된다. 바로 이러한 이유에서 randomized A/B Test가 실험하고자 하는 기능의 성능을 입증하는 표준적인 방법, 즉 “Gold Standard”로 간주되는 것이다.
1.3 무작위 배정이 수행되지 않은 경우
다음으로는 무작위 배정이 수행되지 않았을 때 $\Delta$에 대한 기댓값이 어떻게 구해지는지를 살펴보도록 하겠다.
직관적인 측면에서 생각해보자면, 이 경우에는 앞서 정의한 교란 변수 $\mathbf{X}$ 들의 효과가 대조군과 시험군 사이에 일정하지 않을 가능성이 높아진다. 예를 들어, 대조군에는 미국인들이 많고 시험군에는 아시아인들이 많은 경우, 두 실험 집단의 성질이 통계적으로 균등하다고 보기는 어려울 것이다.
따라서 이러한 경우, 앞서 무작위 배정이 이뤄졌을 때와는 다르게 확률 변수 $Z_i$ 와 $Y_i$ 가 서로 독립이 아니게 된다. 그리고 이는 대조군과 시험군 간 교랸 변수의 불균형이 발생하기 때문이라고 파악할 수 있다.
이제 $\Delta$에 대한 기댓값은 다음과 같아진다.
즉, 위 전개 과정에서 두 번째 등식이 성립하지 않기 때문에 이전과는 다르게 단순히 두 그룹간의 표본 평균의 차이로 $\Delta$를 추정하는 것이 불가능해진다.
이러한 맥락에서 Rubin 교수가 제안한 성향 점수 분석 (Propensity Score Analysis) 의 핵심적인 아이디어는 바로 대조군과 시험군 사이의 교란 변수의 불균형을 인위적으로 보정해주어 위 식에서 두 번째 등식이 성립하도록 만드는 것이다. 이에 대해 자세히 살펴보자.
2. Propensity Score Analysis 개요
앞서 무작위 배정이 수행되었을 경우 $\Delta$, 즉 average treatment effect (ATE) 에 대한 인과적인 결론을 얻을 수 있다는 것에 대한 이론적 증명을 살펴보았다. 그리고 이와는 반대로, 무작위 배정이 수행되지 않은 관찰 연구의 경우에는 ATE가 단순히 대조군과 시험군의 평균 차이로 구해지지 않는다는 점도 살펴보았다.
이러한 맥락에서 “관찰 연구” 를 개념적으로 다시 한번 명확하게 정의하자면, 이는 궁극적으로 어떠한 유저가 대조군 또는 시험군에 배정될지가 랜덤하게 정해지지 않은 것을 의미한다.
한 가지 예를 들어보겠다. 가령, 우리나라에서 안드로이드 핸드폰을 사용하는 유저들과 아이폰을 사용하는 유저들의 연령대에는 다소 차이가 있을 것이라고 추측해볼 수 있다. 이러한 상황에서 만약 각 핸드폰 종류별로 매출액이라는 지표를 잡으면 어떻게 될까? 이 때 매출액은 우리가 실험하고자 하는 핸드폰 기종 (안드로이드 vs 아이폰) 과 별개로 “나이”라는 변수의 영향을 받아 다소 차이가 날 수 있게 된다.
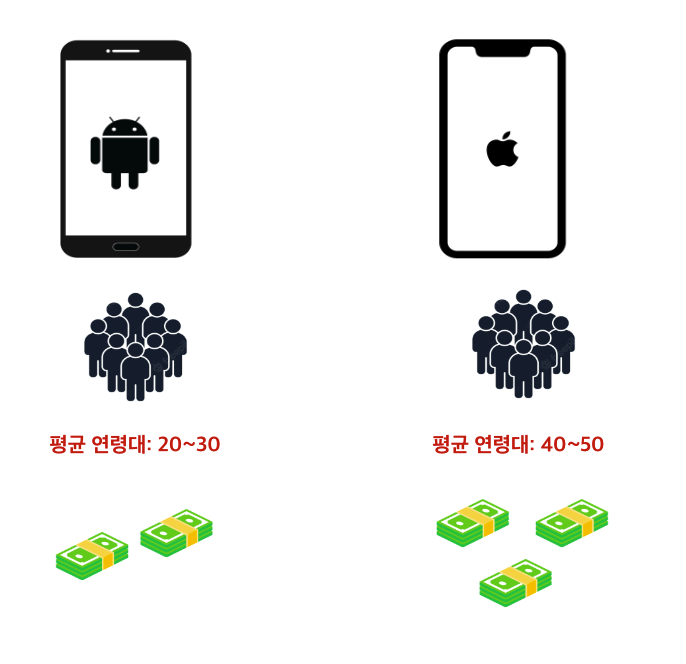
이처럼 관찰 연구는 대조군과 시험군간 유저들의 특징이 균등하지 않을 가능성이 높다는 점이 그 특징이다. 앞서 언급한 것처럼, 통계학에서는 이러한 특징들을 교란 변수라고 정의하며 이로 인하여 원인 변수와 결과 변수 간의 인과 관계를 추론하는 것이 어려워진다.
이와 관련해서 성향 점수 분석 (Propensity Score Analysis) 의 핵심 아이디어는 바로 이렇게 그룹간 일정하지 않은 교란 변수들을 임의로 비슷한 수준으로 만들어 분석을 수행하자는 것이다. 뒤에 다시 살펴보겠지만, 이렇게 일정한 기준(층)으로 집계된 데이터는 일종의 “층화 무작위배정 (stratified random sampling)” 을 통해서 얻어진 데이터로 간주할 수 있기 때문에 이를 바탕으로 각 그룹별 결과 변수에 대한 인과적 효과를 추정할 수 있게 된다.
2.1. 예시
그렇다면 이러한 아이디어가 왜 타당한지를 직관적으로 이해하기 위해서 구체적인 사례를 하나 들어보겠다. 해당 사례는 Rubin의 책 4장에 나와 있는 예시를 약간 수정한 것이며, 시뮬레이션을 통해 만들어진 “가상의” 무작위 배정 실험 데이터이다.
가령, 실험하고자 하는 새로운 기능에 대한 전환율을 살펴보기 위한 실험에서 아래와 같은 데이터를 얻었다고 가정하겠다. 단, 한 가지 주의할 점은 바로 해당 데이터는 하위군 분석에 대한 데이터이며, 구체적으로는 총 두개의 하위군 1) 연령대 (청년층, 중년층) , 2) 성별 (남성, 여성) 이 고려되었다. 따라서 이러한 하위군들의 가능한 모든 조합, 즉 “청년층 남성”, “청년층 여성”, “중년층 남성”, “중년층 여성”에 대해서 총 4개의 실험 데이터가 얻어진 것이다.
구체적인 데이터는 다음과 같다.
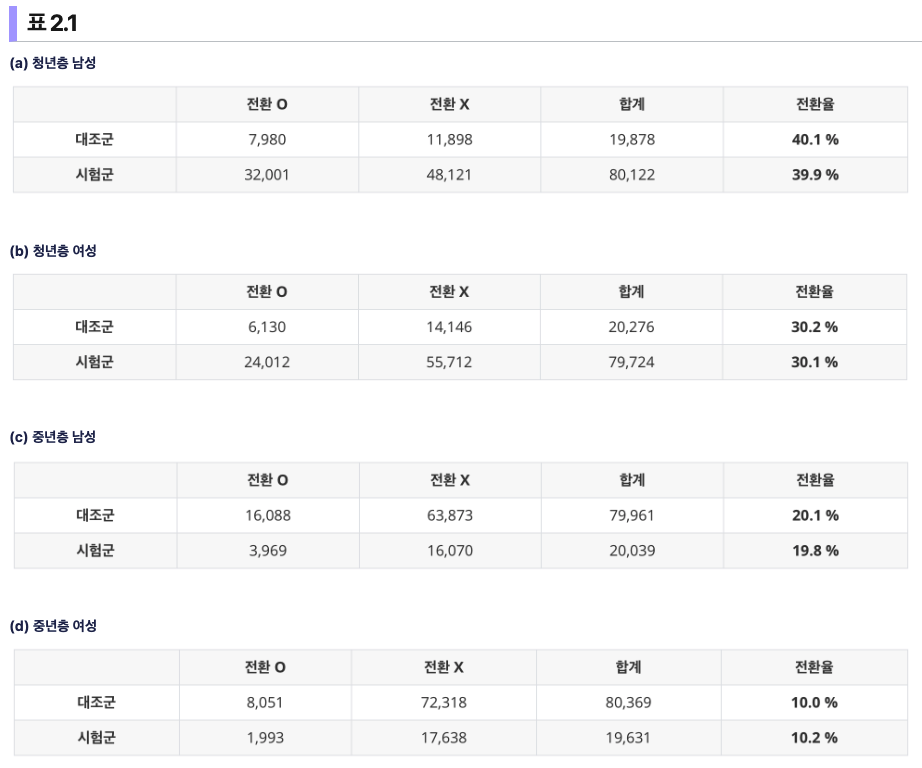
표 2.1에서 확인할 수 있듯이, 각 하위군에서 대조군과 시험군 간에 실제 전환율의 차이는 없다고 가정되었으며, 각 하위군 별로는 무작위 배정이 수행되고 있다. 구체적으로, 청년층 남성 (a) 에 대한 실험에서 대조군과 시험군은 약 $2:8$ 의 비율로 무작위 배정이 이뤄졌다. 나머지 하위군에서도 비슷하게 대조군과 시험군의 비율이 (b)에서는 $2:8$, 그리고 (c)와 (d)에서는 $8:2$ 이다.
이렇게 각 하위군별로 시험군과 대조군의 비율을 다르게 설정한 이유는 바로 위와 같은 데이터를 하나로 합쳤을 시에 어떤 문제점이 발생하는지를 알아보기 위함인데, 이는 총 4개의 하위군에 대해서는 모두 무작위 배정이 제대로 수행되었음에도 불구하고, 이를 “성별”과 “연령대”라는 변수를 무시하고 하나로 합칠 경우 무작위 배정의 효과가 깨지고 실험의 결과가 왜곡될 수 있다는 점이다 (아래 참고).

이렇게 결과가 왜곡되는 현상을 심슨의 역설 (Simpson’s paradox) 이라고 표현하는데, 위와 같은 데이터가 바로 관찰 연구를 통해서 얻어진 데이터라고 할 수 있다.
이와 관련해서 성향 점수 분석은 관찰 연구의 데이터로부터 표 2.1과 같은 형태로 분해된 하위군을 얻기 위한 방법론이라고 이해할 수 있다. 이제 성향 점수 분석의 핵심을 이해하기 위해서 교란 변수의 정의를 구체적으로 살펴보도록 하겠다.
2.2. 교란 변수
앞서 관찰 연구에서의 교란 변수란, 어떠한 실험에서 원인 변수와 결과 변수 모두에 영향을 미치는 변수라는 점을 살펴보았다.
이러한 맥락에서 표 2.1을 바탕으로 “연령대”와 “성별” 이라는 두 변수가 과연 교란 변수인지 아닌지를 판단해보도록 하자.
연령대
우선 첫 번째로 “연령대”의 측면에서 표 2.1을 청년층과 중년층으로 분리해서 전환율을 파악해보자.
이렇게 될 경우 우리는 표 2.1을 “(a), (b)” vs “(c), (d)” 로 묶을 수 있으며, 전자는 청년층, 후자는 중년층 그룹이 된다.
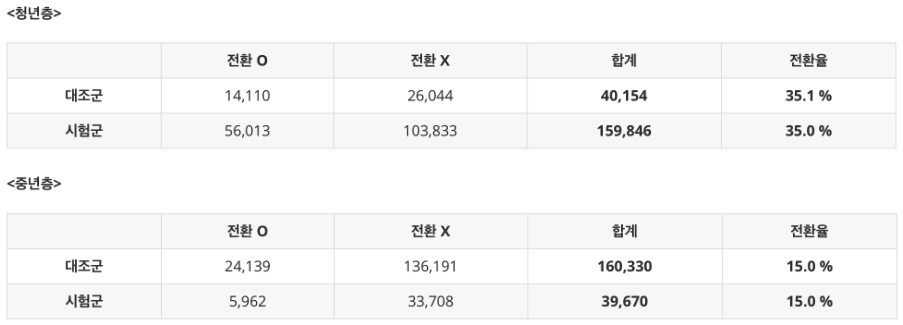
위 표를 통해 우리는 전환율이 청년층에서는 약 35% 인 반면, 중년층에서는 약 15% 로 두 하위군 간 분명한 차이가 있는 것을 확인할 수 있다. 즉, “연령대”라는 변수는 결과 변수 (전환율) 에 영향을 미친다.
비슷한 맥락에서 “연령대”는 원인 변수 (i.e. 대조군 또는 시험군에 배정될 확률) 에도 영향을 미친다고 할 수 있는데, 가령 청년층에서는 대조군과 시험군의 비율이 약 2:8 인 반면, 중년층에서는 8:2 로 차이가 있다.
결론적으로 “연령대”는 결과 변수와 원인 변수 모두에 영향을 주기 때문에 교란 변수라고 결론내릴 수 있다.
성별
다음으로는 “성별”을 살펴보자.
이번에는 표 2.1을 “(a), (c)” vs “(b), (d)”로 묶을 수 있는데, 전자는 남성, 후자는 여성 그룹을 의미한다.
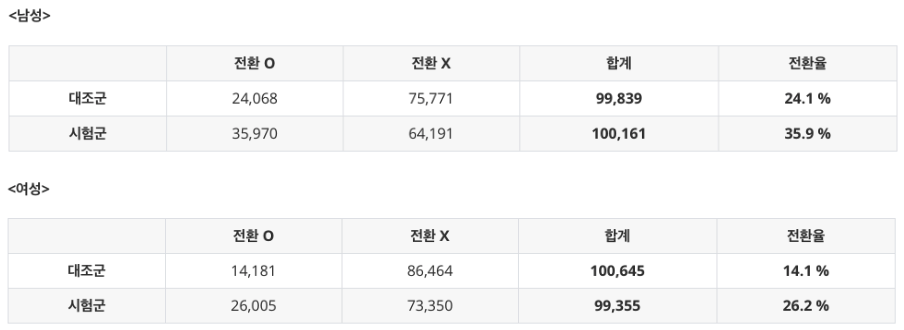
마찬가지로, 결과 변수(전환율)에 대해서 “성별”이 영향을 미치고 있다는 것을 쉽게 확인할 수 있다 (약 30% vs 20%).
하지만 원인 변수인 시험군과 대조군의 배정 확률에 대해서는 남성 그룹과 여성 그룹 모두 50:50 으로 차이가 없다.
이러한 측면에서 “성별”은 오직 결과 변수에만 영향을 미치므로 교란 변수가 아니라고 판단할 수 있다.
2.3. 층화 무작위 배정 (stratified randomization)
그렇다면 위와 같이 교란 변수를 정의하는 것이 왜 중요한지에 대한 이유를 성향 점수 분석의 핵심적인 아이디어인 “층화 무작위 배정”의 개념과 연관지어 살펴보겠다.
우리는 앞서 두 가지 변수가 각각 교란 변수인지 아닌지를 파악했는데, 이 때 “연령대”는 교란 변수인 반면, “성별”은 교란 변수가 아니었다. 또한 표 2.1은 모든 하위군에 대해서 대조군과 시험군에 대한 전환율의 차이가 실제로 없음을 가정하고 생성된 데이터였음을 기억하자.
Case 1) Bias가 발생하지 않는 경우
이러한 맥락에서 교란 변수가 아닌 “성별”의 영향력을 무시하고 “연령대”를 기준으로 집계된 데이터를 다시 한번 살펴보자.
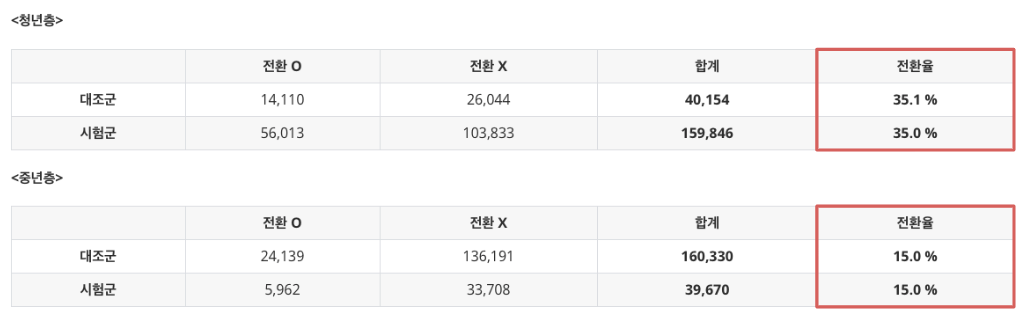
위 표에서 “성별”이라는 변수는 각 연령대별로 합쳐졌기 때문에 더 이상 존재하지 않는다. 그리고 이로부터 확인할 수 있는 점은 원본 데이터와 마찬가지로 대조군과 시험군의 전환율에 차이가 없다는 것이다. 실제로 카이제곱검정을 이용해서 각 연령대 별로 전환율에 대한 가설 검정을 진행해보면 p-value가 0.05보다 커서 귀무가설이 채택되는 것을 확인할 수 있다.
이로부터 알 수 있는 사실은 바로 교란 변수가 아닌 변수들에 대해서는 그 영향력을 무시하더라도 무작위 배정의 비율만 일정하다면 실험의 결과가 왜곡되지 않는다는 점이다.
왜 그런지에 대한 이유를 한번 생각해보자. 이는 원본 데이터(표 2.1)에서 “연령대”라는 변수에 대해서는 무작위 배정이 동일한 비율 (2:8 / 8:2) 로 수행되고 있었기 때문에, 이렇게 동일한 무작위 배정 비율을 갖는 하위군 두개를 합친 데이터 역시 무작위 배정이 수행된 실험 데이터라고 간주할 수 있기 때문이다. 따라서 위처럼 각 연령대별로 분석을 수행하더라도 통계적으로 bias가 발생하지 않는 것이다.
Case 2) Bias가 발생하는 경우
한편, 이번에는 앞서 교란 변수였던 “연령대”를 무시한채로 “성별”에 대해 집계된 데이터를 살펴보도록 하겠다.
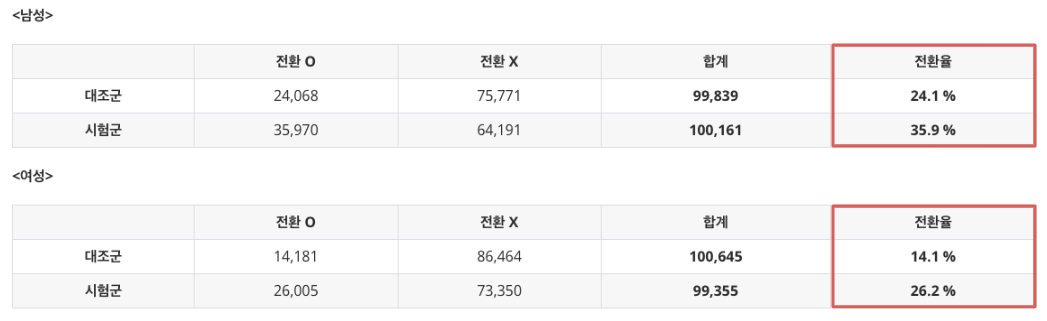
이 경우에는 각 성별별 전환율에 대한 결과가 대조군과 시험군에서 확연히 차이가 있는 것을 확인할 수 있다. 즉, 원본 데이터(표 2.1)에서는 두 그룹간 전환율에 차이가 없었음에도 불구하고 성별에 대해 집계된 데이터에서는 실험의 결과가 달라지는 결과의 왜곡이 발생한 것이다.
왜 이런 bias가 발생한 것일까? 그 이유는 애당초 표 2.1에서 각 성별별로 무작위 배정의 비율이 동일하지 않았기 때문이다. 가령 남성의 경우 청년층에서는 대조군과 시험군의 배정 비율이 2:8이었던 반면, 중년층에서는 비율이 8:2로 서로 차이가 있었는데, 이러한 시험군과 대조군의 배정 비율을 무시한 채 데이터를 하나로 합쳤기 때문에 결과적으로 bias가 발생한 것이다.
여기까지의 내용을 한 마디로 요약하자면 다음과 같다.
» 대조군과 시험군에 대한 무작위 배정 확률이 일정한 하위군에 대해서, 교란 변수를 기준으로 데이터를 집계할 경우 결과에 대한 bias가 발생하지 않는다.
즉, 이렇게 얻어진 데이터는 교란 변수를 기준으로 층화 무작위배정이 수행된 실험 데이터라고 간주할 수 있으며, 이를 바탕으로 원인 변수와 결과 변수간 인과 관계에 대한 통계적 추정이 가능하게 되는 것이다.
이러한 맥락에서 관찰 연구의 데이터로부터 “층화 무작위배정” 된 데이터를 얻기 위해서 필요한 조건들은 다음과 같다.
1) 교란 변수를 정의하는 것
2) 교란 변수를 기준으로 하는 층에서 무작위 배정 확률이 일정한 것
이와 관련해서 Rubin 교수는 모든 교란 변수를 알고 있을 경우 (조건 1), 이를 바탕으로 성향 점수 (propensity score) 라는 것을 정의해서 조건 2를 만족시킬 수 있다는 내용을 수학적으로 증명했다. 이제 본격적으로 그가 제안한 성향 점수 분석을 살펴보도록 하자.
3. 성향 점수 분석 (Propensity Score Analysis)
3.1. 성향 점수 분석의 가정 사항
성향 점수 분석 (i.e. propensity score analysis) 의 가정 사항은 다음과 같다. 구체적인 노테이션은 앞서 정의한 것과 동일하다.
(1) Constancy Assumption
해당 가정은 앞서 살펴본 다음의 식을 의미한다.
다시 한번 리마인드를 해보자면, 위 가정은 만약 $i$ 번째 유저가 시험군에 배정되었을 경우 해당 유저에 대한 실제 관측값은 두 잠재적 결과 중 $Y_i(1)$이 되고, 반대로 대조군에 배정되었을 경우에는 $Y_i(0)$가 된다는 내용이다.
사실 이는 어찌보면 당연한 소리처럼 보이는데, 만약 $i$번째 유저가 시험군에 배정되었음에도 불구하고 실제로는 대조군의 기능에 노출되었을 경우 해당 가정이 성립하지 않게 된다. 따라서 플랫폼 구현상의 에러 등이 발생하지 않는 이상 위 내용은 크게 무리는 없는 가정이라고 할 수 있다.
(2) Positivity
이는 실험에 참가하는 유저가 시험군 또는 대조군에 배정될 확률이 양수여야 한다는 조건으로, 이 역시 지극히 당연하다.
수식적으로는 다음과 같이 표현된다.
(3) SUTVA (Stable Unit Treatment Value Assumption)
해당 가정은 한 마디로, 실험에 참여하는 유저들 간 상호 작용이 없어야 한다는 조건이다.
위 가정이 위배되는 경우는 만약 몇몇 유저들간에 일종의 social effect가 있어, 특정한 유저가 시험군의 기능에 노출되었을 경우 다른 유저의 관측값이 이에 영향을 받아 변하는 경우를 들 수 있다.
온라인 A/B Test의 맥락에서 해당 가정 사항 역시 크게 무리가 있는 내용은 아니라고 생각된다.
(4) No unmeasured confounders
이는 특정한 실험에 대한 교란 변수들을 사전에 모두 알고 있다는 가정으로, 앞서 세 가정과는 다르게 다소 비현실적이고 굉장히 strong한 가정 사항이라고 할 수 있다. 그리고 이는 성향점수분석의 가장 큰 약점이다.
해당 가정의 가장 큰 문제점은 바로 관찰 연구에서 실제로 이 가정이 만족되었는지를 객관적으로 판단할 수가 없다는 점인데, 그래서 필자도 개인적으로는 해당 방법에 대해 회의적인 시각을 갖고 있다. (randomized A/B Test가 최고인 이유)
그럼에도 불구하고 성향 점수 분석은 수 많은 (실험 연구를 할 수 없는) 사회과학 분야와 온라인 A/B Test에서 Observational Causal Study의 대표적인 방법론으로 자리매김하고 있다. 실제 성향 점수 분석을 활용한 논문이나, A/B Test의 사례에서는 충분한 사전 자료가 있는 경우에 해당 가정이 만족될 수 있다는 암묵적인 동의가 있는 것으로 보여진다.
3.2. 성향 점수 (propensity score) 의 정의
실험에 참가하는 유저별로, 성향 점수는 다음과 같이 정의된다.
이는 $i$번째 유저의 공변량 $X_i$가 주어진 경우, 해당 유저가 시험군에 배정될 조건부 확률을 의미한다.
사실 성향 점수의 위와 같은 정의는 그 목적이 매우 명확하다고 할 수 있는데, 앞서 살펴본 관찰 연구의 데이터로부터 “층화 무작위 배정”된 것으로 간주할 수 있는 데이터를 얻기 위해서 필요했던 다음의 조건 두 가지를 떠올려보자.
1) 교란 변수를 정의하는 것
2) 교란 변수를 기준으로 하는 층에서 무작위 배정 확률이 일정한 것
이러한 맥락에서 성향 점수는 조건 2) 를 만족시키도록 하기 위해 도입된 지표에 불과하다. 구체적으로, Rubin과 Rosenbaum (1983)은 다음의 사실을 증명했다.
이는 앞서 시험군과 대조군의 평균 차이가 ATE라는 점을 유도하기 위해 필요했던 내용과 대응되는데, 일반적인 무작위 배정 실험에서는 아래의 식이 성립했었음을 기억하자.
따라서 만약 교란 변수를 전부 알고 있는 경우 (no unmeasured confounders 가정), 이를 바탕으로 각 유저에 대해 도출된 성향 점수를 기준으로 앞서 예시에서 살펴본 것처럼 데이터를 집계하게 되면 우리는 궁극적으로 층화 무작위 배정된 데이터를 얻을 수 있게 된다. 그리고 이렇게 집계된 데이터를 바탕으로 일반적인 A/B Test에서 처럼 ATE를 추정할 수 있는 것이다.
3.3. 성향 점수 (propensity score) 의 추정
앞에서 성향 점수는 조건부 확률로 정의된다는 점을 살펴보았는데, 사실 성향점수는 알 수 없는 미지의 값(확률 변수)이므로 실제로는 각 유저별로 관측된 자료를 바탕으로 추정해야 할 대상이다.
그렇다면 구체적으로 어떤 방법을 통해서 성향 점수의 값을 구할 수 있을까?
가장 흔하게 사용되는 방법은 바로 로지스틱 회귀 모형을 이용하는 것이다. 앞서 성향 점수란, 공변량이 주어졌을 때 각 유저가 시험군에 배정될 “확률”로 정의된다는 점을 기억하자. 이러한 맥락에서 자연스럽게 시험군의 배정 여부를 나타내는 binary 변수 $Z_i$ 를 종속 변수로 하고, 주어진 공변량 $\mathbf{X_i}$ 를 독립변수로 하는 로지스틱 회귀 모형을 정의할 수 있다. 이 때, 해당 로지스틱 회귀 모형의 모수가 바로 우리가 구하고자 하는 성향 점수가 되는 것이다.
3.4. Average Treatment Effect (ATE) 의 추정
마지막으로 이렇게 유저별로 정의된 성향 점수를 바탕으로 어떻게 ATE를 추정할 수 있을지에 대해 간략하게 살펴보겠다.
이와 관련해서는 크게 다음의 두가지 방법이 흔히 사용된다.
- stratification
- matching
이를 하나씩 살펴보자.
Stratification
앞서 로지스틱 회귀 모형을 이용해서 총 $n$명의 유저에 대해 (추정된) 성향 점수를 계산했다고 가정하자.
이를 바탕으로, ATE를 추정하는 과정은 다음과 같다.
- 성향 점수가 “유사한” 유저들을 하나의 층으로 분류 (Rubin의 논문에서 사용된 층의 개수는 5개)
- 성향 점수들을 오름차순 또는 내림차순으로 정렬
- 해당 층별로 시험군과 대조군의 평균 차이 $\bar Y$를 계산
- 각 층별 $\bar Y$의 가중 평균으로 ATE를 추정
구체적인 예시를 들자면, 만약 총 100명의 유저가 있는 경우 다음과 같이 총 다섯개의 층이 만들어질 것이며, 각 층마다 시험군과 대조군의 평균의 차이에 대한 추정치를 얻을 수 있을 것이다.
그리고 이러한 층별 평균의 차이를 바탕으로 ATE는 다음과 같이 추정된다.
Matching
앞서 살펴본 stratification과는 다르게, matching 방법은 알고리즘적인 접근법이다.
구체적으로, matching 방법이란 시험군과 대조군에서 추정된 성향 점수의 값이 “비슷한” 유저들을 한 쌍으로 묶어서 해당 쌍에 대한 관측치의 차이를 바탕으로 ATE를 추정하는 것이다. 이러한 matching을 수행하기 위한 알고리즘은 여러개가 있으며 그 중에서 가장 쉽고 흔하게 사용되는 것은 그리디 (greedy) 접근법이다.
그리디 매칭은 $i$번째 유저에 대해서 다음의 식을 푸는 것과 동일하다.
구체적인 예시를 바탕으로 matching 방법 (w/ greedy algorithm) 이 적용되는 과정을 살펴보도록 하겠다. 여기서는 설명의 편의를 위해 시험군과 대조군 별로 각 50명씩의 유저에 대해 다음과 같이 총 100개의 성향 점수가 계산되었다고 가정한다.
이 상황에서 matching을 적용하면 다음과 같이 총 50개의 “시험군 x 대조군” 쌍을 얻을 수 있다 (인덱스는 단순한 예시이다).
이를 바탕으로 ATE에 대한 추정치는 다음과 같이 계산된다.
Reference
- PAUL R. ROSENBAUM, DONALD B. RUBIN, The central role of the propensity score in observational studies for causal effects, Biometrika, Volume 70, Issue 1, April 1983, Pages 41–55, https://doi.org/10.1093/biomet/70.1.41
- Imbens, G., & Rubin, D. (2015). Causal Inference for Statistics, Social, and Biomedical Sciences: An Introduction. Cambridge: Cambridge University Press. doi:10.1017/CBO9781139025751